





I. 서 론
국어 교사의 평가 문항 개발은 다양한 시험 평가 상황에서 상당한 시간과 비용, 노동력을 요구할 뿐만 아니라, 개별 교사의 평가 역량에 따라 그 과정과 결과물의 질적 수준에서 큰 편차를 보인다(Haladyna & Rodriguez, 2013). 특히 학교 현장에서 폭넓게 활용되는 국어과 선다형 평가는 신뢰도 측면에서는 강점을 가지고 있으나, 고차원적 사고력을 포함한 독서 평가의 복합적 요구(Afflerbach, 2017)를 충족하기에는 근본적인 한계를 지닌다. 그럼에도 학교 지필평가에서는 학습자의 독해 역량을 간접적으로 측정하기 위해 선다형 평가 문항이 지속적으로 활용되고 있다. 이러한 선다형 문항의 타당성을 확보하기 위해서는 개별 교사의 높은 전문성과 상당한 시간 투자가 필요하다. Kissi 외(2023)는 교사의 선다형 문항 작성 역량이 문항의 내용 타당도(content validity)와 품질에 직접적으로 영향을 미친다고 강조하였다. 또한, Zimmaro(2010)는 선다형 문항이 객관적이고 효율적인 평가 도구로 활용될 수 있지만, 고품질 문항을 작성하기 위해서는 세심한 설계와 검토 과정이 필수적이라고 지적하였다. 특히, 효과적인 선다형 문항을 개발하려면 학습 목표에 부합하는 명확한 문항 설계와 다양한 난이도를 고려한 정교한 출제 과정이 요구된다.
이러한 문제를 해결하기 위한 방안으로 자동 문항 생성(Automated Item Generation, 이하 AIG) 기술이 주목받고 있다. AIG는 인지 및 심리 측정 이론을 기반으로 컴퓨터 기술을 활용하여 평가 문항을 자동으로 생성하는 기술을 의미한다(Hornke & Habon, 1986; Embretson & Yang, 2007; Gierl & Haladyna, 2012). 이는 평가 문항의 생산성을 높이는 동시에 신뢰성과 공정성을 확보할 수 있는 도구로서, 특히 교사들의 문항 개발 전문성 부족으로 인한 문항 질 저하 문제를 해결할 수 있는 대안으로 제시되어 왔다(Tarrant et al., 2006). AIG 기술의 발전은 교육적 활용 가능성을 크게 확장시키고 문항 개발에 소요되는 시간을 줄이며, 효율적으로 난이도나 측정 요소에 대응하는 문항 개발의 가능성을 확장시키는 데 기여한다(Kurdi et al., 2020).
그러나 기존의 AIG 연구는 주로 템플릿 기반 접근법(Gierl & Lai, 2013)에 의존해 왔으며, 이는 생성된 문항의 유형이 제한적이고 여전히 인간 전문가의 초기 작업에 의존해야 하는 한계를 보였다(von Davier, 2018; Kosh et al., 2019). 이러한 한계를 극복할 수 있는 새로운 가능성으로 생성형 AI 기술이 주목받고 있다. AI 기반 자연어 처리(NLP) 기술의 발전, 특히 GPT-3 및 그 후속 모델(GPT-4 등)과 같은 대규모 언어 모델의 등장은 템플릿 없이도 고품질 문항을 생성할 수 있는 혁신적인 전환점이 되었다. 이러한 모델들은 대량의 텍스트 데이터를 사전 학습한 후 특정 작업에 대한 소량의 예시만으로도 원하는 과제를 수행할 수 있는 ‘퓨샷 학습(few-shot learning)’ 능력을 보여주며(Brown et al., 2020), 교육 평가 영역에서 획기적인 변화를 가져오고 있다.
생성형 AI 기술은 기존 템플릿 기반 접근법의 한계를 효과적으로 극복하며 다음과 같은 세 가지 강점을 보여준다. 첫째, 인간 전문가가 작성한 템플릿 없이도 다양한 유형의 문항을 자유롭게 생성할 수 있다. 둘째, 문항 작성 속도를 획기적으로 높이면서도 일정 수준 이상의 품질을 안정적으로 유지할 수 있다. 셋째, 사전 학습된 방대한 데이터를 기반으로 다양한 언어와 문화적 맥락에 적합한 문항을 생성할 수 있어 평가의 공정성과 접근성 향상에 기여한다(von Davier, 2018; Shin, 2021).
이러한 생성형 AI의 가능성은 교육 평가, 특히 독해 평가 분야에서 구체적인 성과로 입증되고 있다. von Davier(2019)는 GPT-2 모델을 활용하여 의료 면허 시험과 유사한 복잡한 문항을 생성하는 데 성공했으며, 이는 문항 작성의 초기 단계를 자동화함으로써 문항 작성 시간을 대폭 단축하면서도 평가 목표에 부합하는 고품질 문항 생성이 가능함을 보여주었다. 또한 Hommel 외(2021)의 GPT-3를 활용한 성격 평가 문항 개발 연구는, GPT-3가 인간 전문가의 초안을 기반으로 문항을 확장하거나 수정함으로써 평가의 신뢰성을 유지하면서도 문항 개발 과정을 효율화할 수 있음을 입증하였다.
또한 국제 독해력 평가 프로그램인 PIRLS(Progress in International Reading Literacy Study)에서도 생성형 AI의 활용 가능성이 확인되고 있다. Brown 외(2020)는 GPT-3를 활용하여 PIRLS의 문학적・정보적 텍스트 특성을 반영한 독해 자료를 생성하고 이에 기반한 문항을 개발하였다. 연구진들은 생성된 문항의 난이도, 맥락 적합성, 교육적 유용성에 대한 전문가 검토를 통해 생성형 AI가 인간 작성 문항과 비견할 만한 수준의 품질을 유지할 수 있음을 입증하였다. 특히 주목할 만한 것은 최근의 연구들이 보여주는 다양한 접근 방식이다. Shin(2021)은 템플릿 기반 및 비템플릿 기반 기법을 결합하여 문학 작품 기반의 독해 추론 테스트 문항을 개발하였고, Fung 외(2020)는 T5 모델을 활용하여 독해 문항과 문법 관련 다지선다형 문항을 생성하는 웹 시스템을 구축하였다. 또한 Duolingo의 영어 시험(DET)은 GPT-3를 활용하여 설명문과 서사문을 포함한 독해 평가를 자동으로 생성하는 성과를 보여주었다(Attali & Burstein & Tetreault, 2022).
생성형 AI를 활용한 AIG 연구는 국제적으로 활발히 진행되고 있는 반면, 국내 연구는 아직 초기 단계에 머물러 있다. 오규설(2022)이 사실적 독해 문항 모형을 중심으로 자동문항생성 기법의 구체적 적용 방안을 제시한 것을 시작으로, 이하늘, 이용상(2024)은 외국어로서의 한국어 읽기 평가를 위한 AIG 활용 방안을 탐색하였다. 최근 허동석 외(2024)는 GPT-4 모델 API와 커스텀 데이터베이스를 활용한 ‘신속문답생성기’ 시스템을 개발하여 실제적 적용을 시도하였다. 그러나 이러한 연구들은 실제 교육 현장에서 교사들이 직면하는 복합적인 문제들, 즉 지문과 연계된 다수 문항의 생성, 문항 간 간섭현상 방지, 문항 오류 최소화 등의 과제(장성민, 2024)를 해결하는 데는 아직 한계를 보이고 있다.
이러한 맥락에서 본 연구는 생성형 AI를 활용한 AIG 기술의 확장 가능성을 탐색하고자 한다. 특히 제로샷(Zero-shot), 퓨샷(Few-shot), CoT(Chain-of-Thought) 세 가지 프롬프트 유형별로 국어과 읽기 영역 선다형 세트(사실, 추론, 비판, 적용 및 창의) 문항 개발의 가능성을 탐색하고, 현직 국어 교사 및 국어교육 전문가 평가를 통해 생성된 문항의 질을 검증하고자 한다. 본 연구의 구체적인 연구 문제는 다음과 같다.
첫째, 생성형 AI 기반 AIG 기술을 통해 국어과 읽기 영역 평가의 특성을 반영한 세트 문항을 생성할 수 있는가?
둘째, 국어과 읽기 영역 선다형 평가 세트 문항 생성을 위한 CoT, 제로샷, 퓨샷 프롬프트 중 가장 적합한 전략은 무엇인가?
셋째, 생성형 AI 기반 AIG 기술이 국어과 읽기 영역 선다형 평가 세트 문항 생성 과정에서 드러낸 주요 한계는 무엇인가?
이 같은 연구를 통해 학교 현장에서 교사의 문항 개발 전문성을 보조할 수 있는 생성형 AI의 도구적 가능성을 확인하고, 향후 국어과 읽기 영역 선다형 평가 문항 개발의 새로운 방향을 제시할 수 있을 것으로 기대한다.
II. 이론적 배경
자동 문항 생성(AIG)의 체계적 접근은 von Davier(2018)의 신경망 기반 연구에서 시작되었다. 그는 AIG 과정을 사전 준비, 문항 생성, 검토 및 수정, 문항 최적화의 단계로 체계화했는데, 이는 이후 GPT 모델을 활용한 의료 인증 문항 생성 연구(von Davier, 2019)를 통해 더욱 구체화되었다. 사전 준비 단계에서는 평가의 목적, 응시자의 연령 및 능력 수준, 평가하고자 하는 학습 목표를 명확히 정의하고, 대규모 언어 모델에 입력할 프롬프트를 설계한다. 문항 생성 단계에서는 독해 지문을 생성하고 이에 따른 문항과 선택지를 작성하며, 검토 및 수정 단계에서는 전문가 검토를 통해 평가 목표 부합도, 문법적 정확성, 내용 적합성, 논리적 일관성, 난이도 조정, 편향 제거 등을 점검한다. 마지막 문항 최적화 단계에서는 검토 결과를 반영하여 평가 목적에 맞게 문항을 확정한다.
이러한 AIG 절차에서 프롬프트 설계는 생성형 AI 기반 문항 생성의 핵심 요소로 부각된다. Brown 외(2020)는 GPT-3의 few-shot 학습 능력을 입증하며, 프롬프트 입력 방식이 모델 출력 품질에 중요한 영향을 미칠 수 있음을 시사한다. 프롬프트는 AI 모델에게 특정 작업을 수행하도록 지시하는 입력 형태로, 문항 유형, 난이도, 평가 목표 등을 명확히 정의함으로써 AI의 출력을 제어한다. 적절하지 않은 프롬프트 설계는 생성되는 문항의 적합성, 일관성, 난이도가 평가 목적과 부합하지 않을 위험을 초래할 수 있어, AIG의 성공적 구현과 평가 신뢰성을 확보하기 위해 정교한 프롬프트 설계가 필수적이다.
이와 같은 맥락에서 Attali 외(2022)는 Transformer 기반 언어 모델을 활용하여 독해 평가 문항을 자동 생성하는 Interactive Reading Task(IR Task)를 개발하였다. 이 연구는 대형 언어 모델과 심리측정학적 접근법을 결합한 컴퓨테이셔널 심리측정학(computational psychometrics)을 통해 독해 문항 생성을 체계적으로 탐구하였다. 연구진은 반복적인 파일럿 테스트와 대규모 파일럿 연구를 통해 생성된 문항의 품질을 인간 전문가와 심리측정학적 관점에서 평가하였으며, 이를 통해 자동 생성된 문항이 인간 작성 문항에 비견할 만한 수준의 품질을 유지할 수 있음을 입증하였다.
특히 Attali 외(2022)는 프롬프트 설계를 통해 독해 지문과 문항 유형 간의 적합성을 높이는 방법론을 제시하였다. 이들은 Transformer 모델이 긴 맥락을 처리하고 텍스트 내 장거리 어휘 관계를 효과적으로 활용할 수 있다는 점에 주목하여, 독해 지문과 연계된 다지선다형(MC) 문항 및 속성 질문(attribute questions)을 생성하였다. 이러한 접근은 기존 템플릿 기반 접근법보다 더 복잡하고 정보가 풍부한 문항 생성을 가능하게 하였다.
한편, Bezirhan & von Davier(2023)는 PIRLS 평가 지문 생성을 위한 체계적인 프롬프트 설계 연구를 수행하였다. 이들은 목표 설정, 텍스트 유형 명시, 난이도 수준, 주제, 어휘 수준, 문장 길이 등 프롬프트 구성 요소를 체계화하며 AI 기반 자동 문항 생성(AIG)이 국제 학업성취도 평가에서 실질적으로 활용될 가능성을 보여주었다.
프롬프트 설계와 더불어 학습 방식 또한 AIG 성과에 중요한 영향을 미친다. Brown 외(2020)는 퓨샷 학습이 다양한 과제에서 우수한 성능을 보임을 입증하였으며, 이는 독해 평가 문항 생성에서도 높은 활용 가능성을 보여준다. 제로샷 방식은 지시 사항만으로 문항을 생성하는 반면, 퓨샷 방식은 예시를 함께 제공하여 모델이 문항의 구조와 스타일을 학습하도록 한다. Attali 외(2022) 역시 퓨샷 학습 방식을 활용하여 다양한 유형의 독해 평가 문항 생성을 성공적으로 구현하며 그 효과성을 입증하였다.
더 나아가 최근의 프롬프트 연구는 Chain-of-Thought(CoT) 전략이라는 새로운 접근법을 보여주고 있다. Wei 외(2022)와 Huang 외(2022)는 CoT 프롬프트 전략이 대규모 언어 모델의 성능을 획기적으로 향상시킬 수 있음을 발견하였다. 중간 추론 단계를 명시적으로 제공하여 모델이 단계별 논리적 사고를 수행하도록 하는 CoT 방식은 본 연구의 프롬프트 설계에도 중요한 시사점을 제공한다. <표 1>은 이러한 최근 프롬프트 연구 동향을 정리한 것으로, 구체적인 CoT 프롬프트 구조와 설계 방안은 다음 장(Ⅲ. 연구 방법)에서 상세히 다루도록 하겠다.
| 연구자 | 연구 주제 | 주요 내용 | 핵심 기법 | 시사점 |
|---|---|---|---|---|
| Das et al. (2021) | AI 사고 과정 추적 | AI의 논리적 진행 과정을 단계별로 추적 | 단계적 추적 | 연구자의 개입 기회 제공 |
| Wei et al. (2022) | Chain-of-Thought (CoT) 프롬프트 | 복잡한 문제 해결 과정에서 언어 모델 성능 향상 | 중간 추론 단계 제공 | 문제 해결의 정확성과 일관성 증대 |
| Huang et al. (2022) | Inner Monologue | 언어 모델의 중간 피드백 반영 | 중간 피드백 메커니즘 | 정교한 계획 및 추론 수행 |
| Shah (2024) | AI 문항 생성 검증 | AI 문항 생성의 질적 수준 향상 | 다단계 검증 | AI 문항 생성의 체계적 접근 |
III. 연구 방법
본 연구는 AI를 활용한 국어과 읽기 영역의 선다형 문항 생성에 적합한 프롬프트 유형을 탐색하기 위해 ChatGPT 4o를 활용하여 세가지 프롬프트 기법을 비교 분석하였다. 이를 위해 제로샷(Zero-Shot), 퓨샷(Few-Shot), CoT(Chain-of-Thought) 프롬프트의 효과를 평가하고, AI 기반 문항 생성(AIG)에서 보다 효과적인 프롬프트 전략을 탐색하는 것을 그 목적으로 한다.
선행 연구에 따르면 문항의 질적 향상을 위해 제로샷과 퓨샷 프롬프트만을 비교하는 것은 한계가 있을 수 있으며, 전문가가 만족할 만한 결과를 얻기 어려울 가능성이 제기되었다. 또한 단순히 프롬프트를 결합하는 방식은 문항의 질에 부정적인 영향을 미칠 수 있어, 초기부터 오류 가능성을 줄일 수 있는 프롬프트 설계가 필요하다는 점이 논의되었다(허동석 외, 2024). 프롬프트의 정교한 조정이 문항 생성의 품질 향상에 기여할 가능성이 있음을 여러 연구에서 언급한 바 있다(신동광, 2023, 2024; 최숙기, 박종임, 2024; 허동석 외, 2024; 임상묵 외, 2024; 이하늘 외, 2024). 이에 본 연구에서는 파일럿1) 단계를 거쳐 다양한 프롬프트를 적용한 문항 생성을 실험하였다.
본 연구는 국어과 읽기 영역 문항 생성의 복잡성을 고려하여 CoT 전략을 활용함으로써, 계산 비용이 증가하더라도 논리적이고 체계적인 접근이 가능할 가능성이 있음을 검토하였다(Huang et al., 2022). 이는 설명 가능한 AI(XAI)의 구현을 위한 실험적 접근의 일환이며, 생성된 문항의 타당성을 평가하고 문제 요소를 명확히 분석하는 데 기여할 것으로 기대된다. 본 연구에서 비교된 각 프롬프트 유형은 AI의 문항 생성 능력을 다각도로 평가하고 보다 효과적인 프롬프트 전략을 탐색하는 데 활용될 수 있을 것으로 보인다.
제로샷 프롬프트는 AI가 사전 학습 없이 문항을 생성할 수 있도록 최소한의 정보를 제공하는 방식으로 설계되었다. 구체적으로, ① ‘10년 차 국어 교사 및 국어 독서 평가 출제 위원’이라는 페르소나를 설정하고, ② 문항 생성 조건으로 평가 기본 정보, 문항 구성 요건, 지문을 포함하였다. 이를 통해 AI가 국어과 읽기 영역 평가 문항을 생성하는 기본적인 수행 과정을 인지하도록 하였다.
퓨샷 프롬프트는 제로샷 프롬프트의 요소를 포함하면서, 추가적으로 ③ 기출 문항과 해설을 추가 제공하였다. 이는 AI가 기존 평가 문항의 구조적 특징과 출제 패턴을 학습하고 이를 모방하여 새로운 문항을 생성할 수 있도록 돕는다. 이러한 퓨샷은 기존 문항 패턴을 학습하여 재현하는 데 초점을 둔다.
CoT 프롬프트의 특이점은 퓨샷과 동일한 요소를 활용하고 있으나 ③을 제공하는 목적 면에서 차이가 있다. 이는 학습자의 문제 해결 사고 과정을 AI가 직접 수행하도록 단계적 과정에 활용되었다. 파일럿 실험을 통해 AI가 실제 고등학생들의 문제를 풀 때 틀리는 문제가 발생하였다는 점, 이것에 대한 원인을 스스로 분석하여 제시하였을 때 일반적인 학습자들의 어려움과 비슷하기 때문이다(예: 본문 내용의 일부를 꼼꼼하게 읽지 못했습니다. / 제가 ~한 문장을 오해해서 오답을 도출했습니다.). 이러한 반응을 고려하여 이 단계를 AI가 스스로 문제 해결을 학습자의 관점에서 경험하고, 이를 문항 생성 과정에 반영하는 전략으로 활용할 수 있을 것이라 판단하였다. 이는 현장의 숙련된 교사들 역시 출제를 위해 수행하는 선행 과정이다. 이러한 과정은 학습자의 수준을 예측하고 매력적인 오답을 형성하거나 문제 오류를 방지하기 위해 적극적으로 반영하는 인간의 전략이기 때문에 AI 역시 CoT 과정에서 반영함으로써 효과성을 높일 수 있을 것이다. 결과적으로, CoT 프롬프트는 퓨샷과 달리 ③의 요소는 AI가 문제 해결의 논리적 사고 절차를 직접 수행하고 재현하는 것에 초점을 둔다.
또한 CoT 프롬프트는 퓨샷 프롬프트와 동일한 구성 요소를 포함하면서도, 추가적으로 AI의 논리적 사고와 추론 능력을 극대화하기 위한 고차원적 사고 과정을 설계에 반영하였다. CoT 프롬프트는 단순한 데이터 모방 수준에서 벗어나 AI가 스스로 사고 과정을 단계별로 구현하도록 유도하였다. 이를 위해 ①, ②, ③의 요소는 단계별로 나누어 제공되었으며, AI가 출제를 위한 여러 맥락을 이해하고 활용할 수 있는 기반을 마련하는데 중점을 두어 설계하였다. <표 2>에서 CoT 프롬프트의 단계적 내용을 구체화하였으며, 그 구체적 구현 양상의 일부를 [그림 2]에서 제시하였다.
[그림 1]은 퓨샷과 차별되는 CoT 프롬프트의 세부 단계 및 의미를 시각화한 것이고, [그림 2]는 CoT 과정에서 나타난 일부 반응을 제시한 것이다. 본 연구의 CoT 프롬프트 설계는 메타인지적 지식과 경험의 상호작용을 강조한 Flavell(1979)의 메타인지 이론과 계획-수행-자기성찰의 순환적 자기조절 과정을 제시한 Zimmerman(1990)의 자기조절학습 모델을 기반으로, AI의 문항 생성 과정에 인간의 고차원적 사고 과정을 구현하고자 하였다. 이러한 이론적 토대 위에서 AI가 전체 진행 과정을 체계적으로 이해하고 실행할 수 있도록 단계별 설계를 구현하였다.
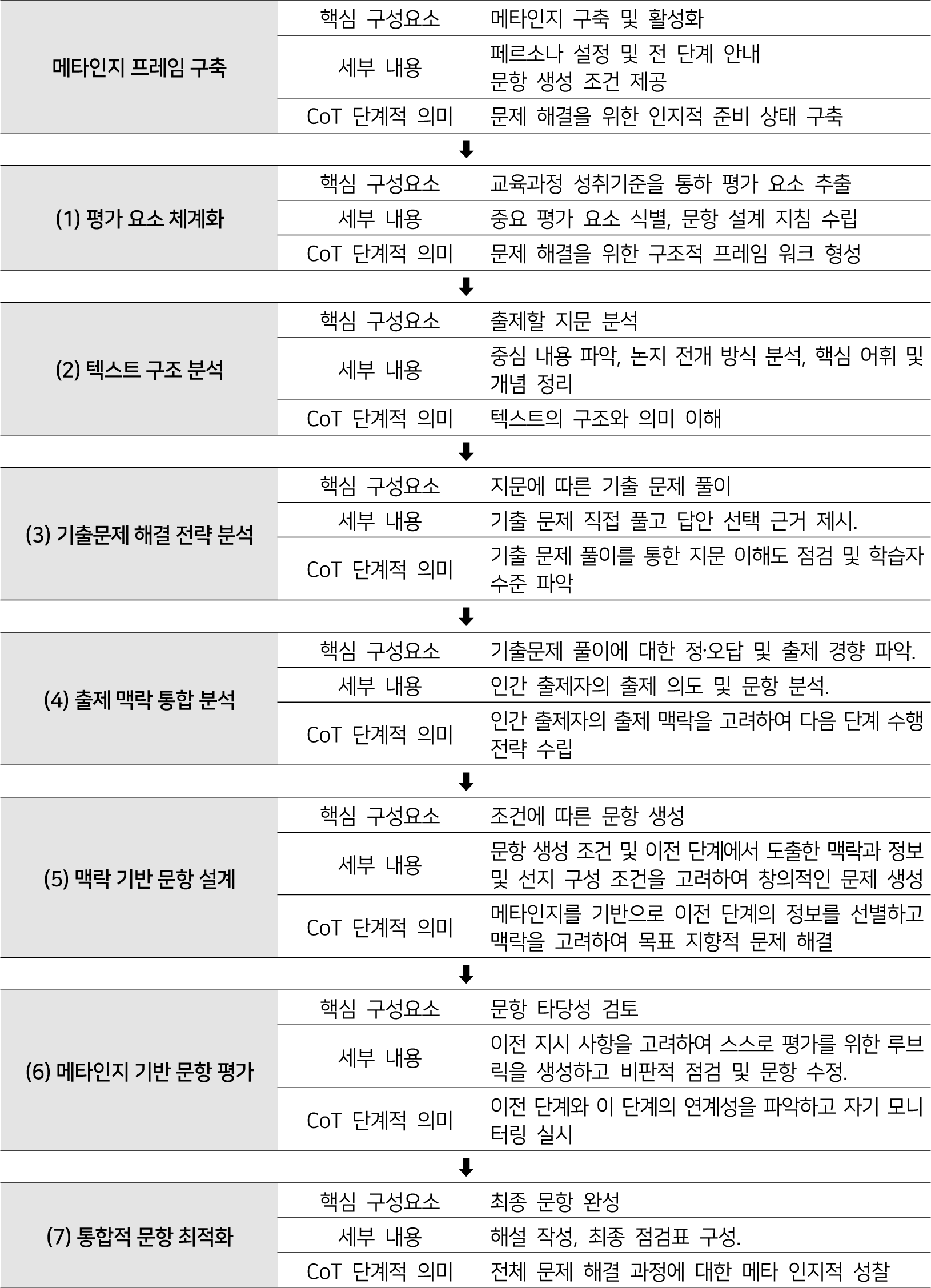

우선 CoT 프롬프트의 초기 단계에서는 교육과정 성취 기준 정보를 제공하여 AI가 이를 분석하도록 하였고, 이해한 내용을 향후 문제 분석 및 출제 과정에 적용하도록 지시하였다. 또한 출제할 지문을 제공하여 텍스트의 중심 내용과 구조를 파악하도록 하였다. 이후 기출 문제를 활용하여 학습자 관점에서 문항을 이해하고, 기출 문제 해설서를 통해 출제 의도를 비판적으로 검토하도록 하였다. 문항 생성 단계에서는 ‘선지 간섭 방지’, ‘지문 내용의 직접 활용 지양’, ‘복수 정답 가능성 제거’, ‘선지 길이의 균형 유지’ 등 세부 지시 사항을 포함하여 AI가 창의적이고 정교한 문항을 설계할 수 있도록 하였다. 자체 검증 단계에서는 생성된 문항의 타당성을 점검하고 필요시 개선하며, 최종 확정 단계에서는 해설과 함께 문항 세트를 완성하도록 구성하였다. 이러한 CoT 전략의 핵심은 단계적으로 진행한 내용들이 향후 수행에 일관성 있게 적용되게 하는 데 있다. 이는 파일럿 과정에서 발견한 AI의 한계를 종합하여 잠정적인 해결안으로써 정리한 내용을 단계에 반영한 것이다.
본 연구에서 설계한 CoT 프롬프트에 반영된 이론적 맥락은 다음과 같다. CoT 프롬프트는 여러 선행 연구에서 보고된 바와 같이 복잡한 논리적 사고를 요구하는 문항에서 AI의 추론 능력을 극대화하는 데 있다(Wei et al., 2022; Huang et al., 2022). 특히 자기 설명(self-explanation) 메커니즘의 일환인 내적 독백(Inner Monologue) 기법은(Huang et al., 2022) 현재 AI가 사고하는 지점과 문제점을 밝혀내고 중간에 인간(교사)이 개입(Das et al., 2021).하여 맥락을 재구성하는 데 도움을 준다. 이를 위해 본 연구에서 CoT의 모든 단계는 AI가 각 단계에서 이해한 내용과 문제 해결을 위해 반영한 사고 과정을 언어로 명확히 표현하도록 지시하였다. 이는 현재의 행위가 선행 단계와 꾸준히 연계성을 지니고 있는지 인간(교사)이 확인하는 데 도움을 준다.
더불어 다단계 검증(Shah, 2024)을 통해 AI 응답의 논리적 일관성을 확보하고자 하였다. 이는 복잡한 처리 과정에서 발생할 수 있는 맥락 상실과 일관성 부족 문제(Funk et al., 2023; Maity et al., 2024)를 보완하기 위한 전략이다. 이를 통해 AI가 문항 생성 과정에서 복잡한 사고 과정을 투명하게 구현하고, 인간 참여자가 AI의 성능과 한계를 체계적으로 평가할 수 있는 기반을 마련하였다.
본 연구는 국어과 읽기 영역 평가에서 특정 분야의 지문을 선정하여 자동 문항 생성(AIG)의 적용 가능성을 심층적으로 분석하는 데 목적이 있다. 읽기 평가는 학습자의 비판적 사고력과 이해력을 확장하는 핵심 과정으로, 수능 국어 시험은 국가 수준의 국어 교육과정을 바탕으로 대학 학습에 필요한 독해 능력을 종합적으로 평가하는 도구로 활용된다(한국교육과정평가원, 2024). 특히 독서 영역은 다양한 분야의 글을 활용하여 학습자의 폭넓은 독해력과 추론 능력을 향상시키도록 설계되어 있으며, 이는 단순한 지식 습득을 넘어 고차원적 사고와 문제 해결력을 요구한다. 인문・예술, 사회・문화, 과학・기술 등 다양한 분야의 글은 각각 학습자의 분석적 사고, 역사적 통찰, 논리적 추론 능력을 강화하는 데 기여한다. 따라서 국어과 독서 평가에서 다양한 분야의 텍스트를 활용하는 것은 평가의 타당성과 공정성을 확보하는 중요한 전략이다.
그러나 본 연구는 AIG의 적용 가능성을 보다 면밀히 검토하기 위해 특정 읽기 영역 분야를 집중적으로 연구할 필요가 있다고 판단하였다. 이를 통해 문항 개발 과정에서 AIG가 가지는 실제적 효용과 한계를 명확히 분석하고자 한다. 이를 위해 본 연구는 ‘2024학년도 10월 고2 전국연합학력평가’ 국어 영역의 30∼34번 문항 지문을 연구 대상으로 선정하였다(<표 3> 참조). 지문 선정 과정에서는 실제 평가 환경에서의 활용 가능성을 우선적으로 고려하였으며, 전문가 집단(현직 교사 3인)과의 사전 인터뷰를 통해 활용의 적절성을 검토하였다. 전문가들은 해당 지문이 실제 지필 평가에서 적용성과 적절성을 갖춘다고 판단하였다. 일부 전문가가 수능 기출 지문의 활용을 제안하기도 했으나, 연구 참여 교사들이 모두 고등학교 2학년을 담당하고 있다는 점과 수능 지문의 난도가 고2 학습자 수준에 비해 상대적으로 높다는 점을 고려하여 이를 배제하였다. 또한 본 연구는 활용된 지문과 문항을 절대적인 질적 우수성보다는 실제 교육 현장에서의 적용 가능성을 중심으로 선정하였다. 현직 교사들의 문항 출제 실태를 고려할 때, 교사들은 대체로 기존 공인된 지문을 활용하여 기출 문항을 변형하거나 평가 문항 유형을 참고하는 경향이 두드러진다. 이에 따라 본 연구는 기존 지문을 제공하는 방식을 채택하였으며, 이는 실제 교육 현장의 평가 실태를 반영하는 실용적인 접근이라고 판단하였다.2)
선정된 <표 3>의 지문은 모든 프롬프트에 공통적으로 제공되었으며, [그림 3]의 기출문제는 퓨샷과 CoT 프롬프트의 학습 자료로 활용되었다. 앞서 설명한 바와 같이 퓨샷은 별도의 지시사항 없이 기출 문제를 제공 받았지만, CoT 프롬프트에서는 AI가 기출문제를 참고하되 동일한 내용의 문제를 출제하지 않도록 명시적으로 지시하였다. 본 연구는 AI가 독해 능력에 대한 기본적 이해를 바탕으로 사실적 이해, 추론적 이해, 비판적 이해, 적용 및 창의적 이해를 반영한 문항을 생성하도록 설계하였다. 특히 생성형 AI의 주요 한계점인 응답 일관성 문제를 고려하여, Funk 외(2023)가 제안한 명시적 지시 사항 제공, 반복 검증 방식, 응답 형식의 표준화 방안을 적용하였다. 구체적으로 2024년 10월 한 달 동안 일정한 시간 간격을 두고 각 프롬프트 유형별로 5회 이상 반복하여 문항을 생성하였다. 이를 통해 각 프롬프트가 보여주는 응답 패턴의 특성을 확인하여 전문가 집단(국어 박사 과정 1명, 국어 교육 독서 전공 교수 2명)의 검토를 거쳐 최종 평가를 받을 각 프롬프트 별 대표 문항 세트를 선정하였다.

본 연구에서는 개발된 국어과 읽기 영역 선다형 평가 문항 생성 결과 평가를 위해 <표 4>와 같이 전문가 집단을 구성하였다. 이 집단은 교육 경력 4~13년의 고등학교 국어 교사 5인과 국어교육 박사과정 연구자 3인으로 구성되었으며, 총 8명의 전문가가 참여하였다. 참여자들은 모두 국어과 읽기 영역 평가 문항의 출제 및 검토 경력을 보유하고 있었고, 연구가 진행되는 시점에서 교사 집단은 고등학교 2학년 독서 과목을 담당하고 있었다. 이러한 배경은 본 연구에서 생성된 문항의 타당성을 평가하는 데 있어 이 집단이 적합한 전문성을 갖추었음을 보여준다. 전문가 집단의 검토와 평가는 연구 결과의 신뢰성과 타당성을 높이는 데 중요한 역할을 하였다.
| 번호 | 성별 | 분류 |
|---|---|---|
| T1 | 남 | 현직 교사 |
| T2 | 여 | 현직 교사 |
| T3 | 여 | 현직 교사 |
| T4 | 여 | 현직 교사 |
| T5 | 여 | 현직 교사 |
| T6 | 남 | 국어교육 박사과정 |
| T7 | 여 | 국어교육 박사과정 |
| T8 | 여 | 국어교육 박사과정 |
본 연구에서는 생성된 문항의 평가를 위해 <표 5>에서 제시된 루브릭을 활용하였다. 해당 루브릭은 문항의 질적 요소를 다각적으로 검토하기 위해 문항 타당성, 문항 형식, 문항 내용의 세 가지 주요 평가 영역으로 구성되며, 각 영역은 두 가지 하위 평가 요소를 포함하고 있다.
먼저, 문항 타당성 평가는 문항이 목표 성취 기준을 적절히 반영하고 있는지, 그리고 학습자의 인지적 수준과 적합한 난이도를 유지하는지를 중심으로 이루어진다. 문항 형식 평가는 문항의 이해 용이성과 기존 기출 문항과의 유사성을 분석하는 데 초점을 둔다. 특히, 기출 문항과의 유사성은 AI가 인간 출제자의 문제 생성 방식과 어느 정도 일치하는지를 판단하기 위한 기준으로 포함되었다. 이는 현직 교사들이 기출 문항을 참고하여 출제하는 경향을 고려하여 설정된 항목으로, AI 기반 문항 생성이 현실적 교육 환경에서 활용될 가능성을 반영한다. 본 연구는 AI가 인간 전문가(교사)의 역할을 대체하는 것이 아니라, 문항 출제 과정에서 보조적 도구로 활용될 가능성을 검토하는 것을 목적으로 한다. 이에 따라, AI가 생성한 문항이 교사의 의도와 출제 전략에 부합하며, 교육적 맥락에서 실제적으로 활용될 수 있는지를 평가하는 것이 연구의 핵심 과제 중 하나이다. 또한 문항 내용 평가는 문항의 정답이 명확하게 설정되어 있는지, 그리고 문항 유형이 다양성을 확보하고 있는지를 분석하는 데 중점을 둔다. 이를 통해 AI가 생성한 문항이 기존의 인간 전문가가 출제한 문항과 비교했을 때 얼마나 다양한 형식으로 구성될 수 있는지를 검토하고자 하였다.
결과적으로, 본 연구에서 활용된 평가 루브릭은 AI 기반 문항 생성이 실제 평가 환경에서 인간의 검토 및 수정을 거친 후 어느 정도 활용 가능할지를 검증하는 데 초점을 두었다. 또한, AI가 생성한 문항이 기존의 인간 출제자가 제작한 문항과 조화를 이루며, 교육적 가치를 유지할 수 있는지를 평가하기 위한 기준으로 설계되었다.
해당 평가는 전문가 집단에 의해 루브릭의 각 항목을 5점 척도(1점: 전혀 아니다 ~ 5점: 매우 그렇다)로 평가되었으며, 평가자 간 신뢰도는 Cronbach’s Alpha .924로 나타나 높은 신뢰도를 보였다. 또한, 전문가들은 전체적인 문항 구성을 검토하여 초안 문항으로 활용 가능한 문항 세트를 선택하였다. 이 과정에서 제로샷, 퓨샷, CoT 프롬프트 유형별로 생성된 문항이 평가되었으며, 필요 시 복수 응답 및 미응답이 가능하도록 안내하여 전문가들이 자유롭게 의견을 제공할 수 있도록 하였다.
이와 함께 본 연구에서는 국어과 읽기 영역 선다형 평가 문항의 결과 평가를 위해 FGI(Focus Group Interview)를 실시하였다. FGI는 전문가들이 작성한 서면 의견서와 심층 인터뷰 자료를 활용하여 문항의 장단점과 개선 방향을 도출하는 데 중점을 두었다. 각 문항 세트에 대해 구체적인 피드백을 수집함으로써 문항의 구조적 및 내용적 특징을 파악하였다. 심층 인터뷰를 통해 각 평가자의 평가 기준, 문항에 대한 세부적인 맥락, 추가적인 개선 의견 등이 수집되었다.
IV. 연구 결과
본 연구는 제로샷, 퓨샷, CoT의 세 가지 프롬프트 유형을 사용하여 고등학교 국어과 읽기 영역 선다형 평가 문항을 생성하고 이를 비교하였다. 연구에 사용된 지문은 ‘2024학년도 고등학교 2학년 전국연합학력평가의 국어 읽기’ 영역 지문으로, 동일한 지문을 각 프롬프트 유형에 제공하여 문항을 생성하였다. 모든 프롬프트는 문항 생성 조건으로 평가 요소를 사실적 이해, 추론적 이해, 비판적 이해, 적용 및 창의적 이해의 네 가지로 설정하고, 각 평가 요소에 맞는 난이도를 조정하여 총 네 문항을 구성하였다.
생성된 문항의 특징을 살펴보면, 제로샷 프롬프트는 주어진 지문 정보를 그대로 활용하여 발문과 선지를 구성하는 단순한 형태를 보였다. 이러한 문항은 간결한 구조를 가지고 있었으나, 학습자의 고차원적 사고를 유도하기에는 한계가 있었다. 퓨샷 프롬프트는 기출문제와 해설을 활용하여 문항의 정교함이 다소 향상되었으며, 관계성을 파악하는 문항을 생성하는 데 효과적이었다. 그러나 여전히 문항의 형식적 다양성과 창의적 요소에서는 부족한 모습을 보였다. CoT 프롬프트는 체계적인 설계를 통해 고차원적 사고와 창의적 문제 해결을 유도하는 문항을 생성하였으며, 사실적 이해에서 창의적 이해에 이르기까지 평가 요소를 균형 있게 반영하였다.
프롬프트 유형별 문항 생성 결과는 CoT 프롬프트가 상대적으로 가장 우수한 성과를 보였으며, 이는 AI 프롬프트 설계의 체계성과 세부 설계가 문항 생성에 미치는 영향을 보여준다. 이 결과를 바탕으로 이어지는 분석에서는 생성된 문항의 질적 특성을 구체적으로 논의할 것이다.
각 프롬프트 유형별로 생성된 국어과 읽기 영역 선다형 평가 문항에 대한 전문가 평가 결과를 정리하면 <표 7>과 같다. 먼저 CoT 방식은 문항 개발에서 가장 높은 성과를 보였다. CoT는 30점 만점에 평균 점수 27.57점으로 모든 프롬프트 유형 중 가장 높은 점수를 기록하였으며, 제로샷 프롬프트의 경우는 가장 낮은 점수를 기록했다. 이를 통해 국어과 읽기 영역 선다형 문항 평가 생성에서 CoT 방식이 가장 높은 성능을 보이는 프롬프트인 것으로 나타났다.
| 제로샷 | 퓨샷 | CoT | |
|---|---|---|---|
| 평균 | 17.57 | 21.86 | 27.57 |
| 표준편차 | 4.31 | 2.59 | 3.44 |
| 최솟값 | 8 | 16 | 18 |
| 최댓값 | 23 | 24 | 28 |
이러한 프롬프트 유형별로 생성된 국어과 읽기 영역 평가 문항의 상대적 질적 차이에 대한 통계적 유의성을 검증하기 위해 일원분산분석(ANOVA)을 실시하였으며, 결과는<표 8>과 같다. F값은 42.076(p<.001)로 나타나 통계적으로 세 프롬프트 유형간 생성된 국어과 읽기 영역 문항의 상대적 질적 차이가 있는 것으로 확인되었다. 일원분산분석 이후 다중 비교를 수행하기 위해서 Scheffé 사후검정 분석을 실시하였다. 그 결과, CoT가 제로샷과 퓨샷에 비해 가장 높은 효과를 보이는 것으로 나타났다. CoT은 제로샷과의 평균 차이(1.458), 퓨샷과의 평균 차이(0.833)에서 모두 통계적으로 유의미한 차이를 보였으며, Scheffé 통계량에서도 가장 큰 값을 기록하였다. 따라서, CoT의 성능이 가장 우수하다고 할 수 있다.
| 프롬프트 유형 | N | 평균 | 표준편차 | F | 유의확률 |
|---|---|---|---|---|---|
| 제로샷 | 48 | 2.563 | 0.897 | 42.076 | <0.001 |
| 퓨샷 | 48 | 3.188 | 0.673 | ||
| CoT | 48 | 4.021 | 0.758 |
| 집단비교 | 평균차이 | Scheffé 통계량 | 기준값 | 유의확률 |
|---|---|---|---|---|
| 제로샷 vs 퓨삿 | 0.625 | 3.86 | 1.21 | <0.001 |
| 제로샷 vs CoT | 1.458 | 8.61 | 1.21 | <0.001 |
| 퓨삿 vs Cot | 0.833 | 5.70 | 1.21 | <0.001 |
전체 지표값에 대한 통계적 유의성 검증에 이어, 세부 평가 항목별로 국어과 읽기 영역 평가 문항과 문항의 질에 대한 심층 분석을 수행하였다. <표 9>는 각 세부 항목의 기초 통계량과 분산분석 결과를 제시하고 있으며, 항목별로 일원분산분석(ANOVA)을 통해 그룹 간 차이를 검토한 후, Scheffé 사후 검정을 통해 그룹 간 세부 차이를 추가적으로 분석하였다.
분석 결과, 3. 문항 이해 용이성을 제외한 모든 항목에서 F값이 통계적으로 유의미한 차이를 보였으며, CoT가 전반적으로 가장 우수한 성능을 나타냈다. 특히, Scheffé 사후 검정 결과에 따르면 CoT는 모든 항목에서 다른 그룹(제로샷, 퓨샷)과 명확한 성능 차이를 보여주었으며, 이는 CoT가 초고 문항으로써 인간 전문가(출제 교사)와 협력하면 국어과 읽기 영역 평가 문항의 질적 향상에 긍정적인 영향을 미칠 수 있음을 시사한다. 한편, 3. 문항의 이해 용이성 항목에서는 제로샷과 퓨샷 간의 성능 차이가 통계적으로 유의하지 않은 것으로 나타났으나, 나머지 항목에서는 CoT가 다른 그룹에 비해 일관되게 우수한 성능을 보였다. 이러한 결과는 CoT 접근 방식이 국어과 읽기 영역 평가 세트 문항 생성에 상대적으로 우수한 성과를 보이며, 향후 AIG 기술 발전을 위한 프롬프트 전략으로 심화된 탐색을 수행할만한 것임을 설명한다.
본 연구는 생성형 AI를 활용한 프롬프트 기반의 AIG 기술을 활용하여 국어과 읽기 영역 평가 문항 생성의 자동화 가능성을 명확히 보여주었다. 연구 결과, 생성형 AI가 생성한 문항은 평가 문항 초안으로 활용될 가능성을 가지고 있으며, 이는 연구에 참여한 전문가들 사이에서도 일정 부분 합의된 내용이었다. 특히 CoT 프롬프트는 문항 세트 생성 과정에서 가장 높은 평가를 받았으며, 사실적 이해와 추론적 이해 문항에서 비교적 우수한 성과를 보여 초안 작성 도구로서의 가능성을 입증하였다. CoT 방식은 AI의 단계적 사고 유도 설계를 통해 발문과 선지 간의 논리적 일관성을 유지하고 지문을 효과적으로 반영하여 문항을 구성하는 데 적합한 전략으로 평가되었다.
그러나 CoT 프롬프트도 모든 평가 항목에서 일관된 성과를 보인 것은 아니었다. 비판적 이해 문항에서는 성취 기준을 형식적으로 반영하는 데 그쳤으며, 발문과 선지가 충분히 구체적이지 않다는 평가를 받았다. 전문가 평가에서는 비판적 사고를 유도하는 문항 설계에서 맥락 제공 부족과 사고 유도의 제한이 CoT 방식의 주요 한계로 지적되었다. 예컨대 T7은 발문 뒤에 대화나 토론과 같은 추가적인 맥락을 제공할 경우, 학습자의 사고를 더욱 깊이 자극할 수 있을 것이라고 언급하며, AI가 국어과 읽기 영역 평가 문항의 복합적 요구를 완전히 충족하지 못했음을 지적하였다.
제로샷 프롬프트와 퓨샷 프롬프트는 AI 기반 문항 생성의 가능성을 보여주었으나, 세트 문항 생성을 위한 전략으로는 한계를 드러냈다. 제로샷 프롬프트는 단순 정보 확인에 치중된 문항을 생성하며, 학습자의 사고를 충분히 유도하지 못했다는 평가를 받았다. T1과 T2는 제로샷 문항이 지문 내 정보를 단순히 재구성하는 경향이 강하며, 난이도가 지나치게 낮아 학습자 수준과 맞지 않는다고 평가하였다. 이러한 결과는 제로샷 방식이 효율적인 초안 작성 도구로 활용될 수 있으나, 고차원적 독해력을 평가하는 문항 설계에는 적합하지 않음을 시사한다.
퓨샷 프롬프트는 기출문제와 해설을 학습 자료로 활용하여 안정적이고 형식적으로 완결된 문항을 생성할 수 있었지만, 창의적 평가 요소를 구현하거나 복합적 문제 해결을 유도하는 데는 한계를 보였다. 전문가 T5는 퓨샷 문항에서 선지 간섭 현상이 발생하여 문항 구조의 완결성이 저해된 사례를 언급하며, 퓨샷 방식이 기존 데이터를 모방하는 데 의존적이라고 평가하였다. 이로 인해 퓨샷 프롬프트는 특정 유형의 안정적 문항 생성을 지원하는 데 유용하지만, 세트 문항 설계와 같은 복잡한 평가 요구를 충족하기에는 부적합하였다.
연구 결과, 생성형 AI를 활용한 프롬프트 활용을 통해 자동 문항 생성(AIG) 기술이 보다 향상될 가능성을 보여준다. 이를 위해 반영해야 할 프롬프트는 CoT 전략이다. 이는 사실적 이해와 추론적 이해 문항에서 가장 높은 평가를 받았다는 점과 세트 문항 생성을 위해 효과적인 프롬프트 전략임을 확인하였다는 점을 주목할 필요가 있다. 그러나 CoT 방식도 특정 평가 요소에서는 한계를 드러냈으며, 인간 전문가의 개입이 필요하다는 점을 연구 결과 전반에 걸쳐 강조되었다. 비판적 이해와 같은 고차원적 사고를 평가하는 문항에서는 인간 전문가가 필수적으로 문항의 맥락과 구조를 보완할 필요가 있다.
결론적으로, AI 기술만으로는 고차원적 평가 요소를 완전히 충족시키기 어렵기 때문에, 문항 설계 과정에서 인간 전문가와의 협업이 요구됨을 확인할 수 있다. 이러한 연구 결과는 향후 국어과 읽기 영역 선다형 평가 문항 생성을 보다 정교하고 효과적으로 발전시키기 위한 AI와 인간의 상호 보완적 접근의 필요성을 명확히 보여준다.
V. 결론 및 제언
본 연구는 국어과 읽기 영역의 선다형 평가 문항 자동 생성에서 AI 프롬프트 전략(제로샷, 퓨샷, Chain-of-Thought(CoT))의 효과를 비교 분석하였다. 이를 위해 세 가지 프롬프트 전략을 적용하여 생성된 문항을 전문가 평가를 통해 검증하였으며, 문항의 형식적 적절성, 논리적 타당성, 평가 목적과의 정합성을 중심으로 분석하였다(Min et al., 2022). 연구 결과, CoT 프롬프트는 AI의 단계적 사고 과정을 유도함으로써 문항의 논리적 일관성을 높이는 데 가장 효과적인 전략으로 확인되었다. CoT 기반 문항은 단순 정보 재구성을 넘어 개념 간의 관계를 논리적으로 조직하여 평가 목표에 부합하는 문항을 생성하는 데 기여하였다(Chen et al., 2023). 이에 반해, 제로샷 프롬프트는 평가 목표와의 부합성이 낮으며, 고차원적 사고를 평가하는 데 한계를 보였다. 퓨샷 프롬프트는 형식적 완결성이 높았으나, 사고 수준의 다양성을 반영하는 데 제한이 있었다(Cai et al., 2023). 이러한 결과는 AI 기반 문항 생성의 실효성을 극대화하기 위해서는 단순한 데이터 입력 방식이 아닌, AI의 사고 과정을 조정하는 정교한 프롬프트 설계가 필수적임을 시사한다. 또한, 문항 생성 과정에서 교사의 개입을 통해 문항의 평가 적합성을 보완하는 Human-in-the-Loop(HITL) 접근이 필요할 것으로 보인다(Min et al., 2022).
본 연구는 AI 기반 자동 문항 생성(AIG)의 가능성을 탐색하는 데 초점을 맞추었으나, 다음과 같은 한계를 가진다. 첫째, 전문가 평가단이 8명으로 제한되어 있어 평가 결과의 일반화 가능성이 낮다. 보다 다양한 전문가 집단이 참여하였다면 연구 결과의 신뢰성과 타당성을 높일 수 있었을 것이다. 둘째, 연구에서는 특정 지문과 평가 상황에서 생성된 문항을 분석하였기에, 다양한 평가 맥락과 학습자 수준에서의 적용 가능성을 충분히 검증하지 못하였다. 셋째, AI가 생성한 문항에 대한 학습자 반응 데이터를 수집하지 못했기 때문에, 실제 평가 상황에서의 효과성을 확인하는 데 한계가 있었다. 향후 연구에서는 학습자의 응답 데이터를 수집하여 AI 기반 문항 생성이 평가 결과에 미치는 영향을 보다 면밀하게 분석할 필요가 있다. 이러한 한계를 고려할 때, 생성형 AI 기술은 독자적으로 완벽한 평가 문항을 생성하는 것이 아니라 교사의 평가 전문성을 보조하는 도구로서 보다 효과적으로 활용될 가능성이 높다. 본 연구에서 확인한 바와 같이, CoT 전략을 활용한 문항 생성은 교사의 검토와 수정 과정을 거칠 때 평가의 논리적 일관성과 타당성을 높이는 데 기여할 수 있다. 이는 AI 기술이 단순한 평가 자동화 도구를 넘어 교사의 평가 역량을 보완하고, 교육 평가의 질적 향상을 지원하는 방향으로 발전해야 함을 시사한다.
이를 고려하여 AI 기반 자동 문항 생성(AIG) 기술의 실효성을 높이고 연구의 한계를 극복하기 위해 다음과 같은 방안을 제안한다.
첫째, AI 기반 문항 생성 기술의 신뢰성과 타당성을 극대화하기 위해 사고 과정의 연계를 체계적으로 반영한 프롬프트 설계가 필수적이다. 정민주 외(2022)의 연구는 국어과 평가 문항의 질적 특성을 분석하며, 문항의 평가 적합성과 신뢰도를 높이는 데 필요한 기준을 제시하였다. 이를 반영하여, AI 기반 문항 설계에서는 국어과 평가 문항이 요구하는 사고 과정뿐만 아니라, 교육과정에서 강조하는 핵심 역량(예: 비판적 사고, 논리적 사고 등)을 반영하는 방식으로 접근해야 한다. 이러한 기준은 AI 기반 문항 설계의 평가 적합성을 보장하는 중요한 요소로 작용해야 한다. 또한 Flavell(1979)은 메타인지적 사고 과정이 평가 문항의 질을 결정하는 핵심 요인임을 강조하였으며, AI 기반 문항 설계에서도 이러한 요소가 적절히 반영될 필요가 있다. 특히, AI 기반 문항 생성은 단순한 정보 확인을 넘어, 추론 및 비판적 분석을 포함한 다양한 사고 과정을 유도하는 방향으로 설계될 필요가 있다. 이를 위해 본 연구에서 CoT(Chain-of-Thought) 프롬프트를 활용하여 문항 간 논리적 연계를 보장하는 방안을 실험적으로 검토한 결과, 프롬프트 설계가 문항의 사고 과정 연계에 중요한 영향을 미친다는 점이 확인되었다(Gierl & Lai, 2013; Burstein, 2023; Zimmerman, 1990).
그러나 본 연구에서 구축한 프롬프트 설계는 보완해야할 측면을 내포하고 있으며, 향후 연구에서는 이를 개선하기 위한 구체적인 전략이 필요하다(Attali et al., 2022; Maity et al., 2024). 예를 들어, 논설문 기반 세트 문항에서는 첫 번째 문항이 핵심 주장과 근거를 식별하도록 하고, 이후 문항들이 논증의 타당성 평가 및 반박 구조 분석으로 확장될 수 있도록 설계해야 한다. 설명문 기반 문항에서는 개념 간 관계를 점진적으로 파악할 수 있도록 계층적 사고를 유도하는 방식이 요구된다(Chen et al., 2023). 이러한 설계를 실현하기 위해 평가 전문가의 피드백을 반영한 동적 프롬프트 튜닝(dynamic prompt tuning) 기법을 적용해야 한다. 이를 통해 AI가 생성하는 세트 문항이 개별적으로 완결성을 가지면서도, 평가 목표와의 정합성을 유지할 수 있도록 해야 한다. 궁극적으로, AI 기반 문항 생성의 효과성을 극대화하기 위해서는 평가 문항의 형식적 완결성과 사고 과정 연계성을 동시에 확보하는 연구가 지속적으로 이루어져야 한다.
둘째, AI 기반 문항 생성의 신뢰성과 타당성을 확보하기 위해 Human-in-the-Loop (HITL) 모델을 체계적으로 구축해야 한다. AI가 생성한 문항은 교육과정 및 평가 기준과의 정합성을 유지해야 하며, 이를 위해 교사와 평가 전문가가 적극적으로 개입하는 HITL 모델이 필수적이다(Attali et al., 2022; Embretson & Yang, 2006; Kissi et al., 2023; 최숙기, 박종임, 2024). 따라서 AI 기반 문항 생성을 교육과정과의 정합성을 고려하여 HITL(Human-in-the-Loop) 모델을 적용해야 한다. 예를 들어, 설명문 기반 문항에서 선택지 간 의미적 유사성이 지나치게 높거나 정답과 오답의 변별력이 낮은 경우, 교사가 이를 수정하는 절차를 명확히 마련해야 한다. 또한, 교사의 피드백을 AI가 학습하여 반복적으로 품질을 개선하는 보정 모델(adaptive refinement model)을 적용할 수 있다. 이 과정에서 AI는 단순히 문항을 생성하는 도구에 머무르지 않고 지속적으로 발전하는 평가 지원 시스템으로 기능할 수 있다. 특히, 추론형 문항에서는 학습자의 기존 반응 데이터를 활용해 정답 선택률과 오답 패턴을 분석하고, 이를 기반으로 변별력이 높은 문항을 생성하도록 조정해야 한다(Gierl & Haladyna, 2013). 이러한 HITL 모델은 교사와 AI 간 협업 체계를 강화하며, AI가 교육 현장에서 신뢰받는 도구로 자리 잡는 데 기여할 것이다.
셋째, 학습자 반응 데이터를 활용한 실증 연구를 통해 AI 기반 문항 생성 기술의 효과성을 검증해야 한다(Kurdi et al., 2020). 본 연구는 AI가 생성한 문항의 형식적 적절성과 논리적 일관성은 주로 전문가 평가에 의존하고 있다. 그러나 학습자 반응 데이터를 활용하여 실제 평가 상황에서 AI 문항이 독해력 측정에 미치는 영향을 분석하는 연구가 필요하다(Kurdi et al., 2020; Funk et al., 2023). 예를 들어, 논설문 문항이 논증 구조를 정확히 반영하는지 또는 설명문 문항이 개념 간 관계를 적절히 평가하는지를 학습자의 정답 및 오답 패턴과 비교하여 검증할 수 있다(Bezirhan & von Davier, 2023). 또한, 특정 인지 과정(예: 추론, 비판적 사고 등)을 효과적으로 유도하는지를 확인함으로써 AI 기술의 교육적 가치를 보다 명확히 입증할 수 있다(Flavell, 1979; Shah, 2024).
넷째, AI가 신뢰성 있는 문항을 생성하기 위해서는 다양한 난이도와 평가 요소를 반영한 대규모 데이터셋 구축이 필수적이다(Kosh et al., 2019; von Davier, 2018; Gierl & Haladyna, 2013; Embretson & Yang, 2006). 이러한 데이터셋에는 단순히 텍스트 자료뿐만 아니라 문항의 메타데이터(metadata)를 포함해야 한다. 메타데이터는 문항의 난이도, 변별도, 평가 목표, 텍스트 유형(예: 논설문, 설명문), 학습자의 인지 수준 등을 상세히 기술한 정보를 의미한다. 예를 들어, 독해력 수준별로 분류된 문항 데이터셋과 함께 각 문항의 난이도 수준(쉬움, 보통, 어려움), 평가 기준(사실 확인, 추론, 비판적 분석), 그리고 학습자가 해당 문항에서 보인 정답률과 오답 패턴 같은 학습자 반응 데이터를 포함해야 한다. 특히, 공신력 있는 기출문제 데이터(예: 대학수학능력시험 및 국가 공인 시험)와 함께 이러한 메타데이터를 포함하면 AI가 문항 생성 시 평가 목표와 학습자 수준에 더욱 정밀하게 부합하는 결과를 도출할 수 있다(Bezirhan & von Davier, 2023; National Academies of Sciences, Engineering, and Medicine, 2022). Embretson & Yang(2006)의 연구는 자동 문항 생성(AIG)의 신뢰성을 높이기 위해 문항 속성과 평가 모델 간의 체계적인 연계를 강조했으며, 이를 기반으로 AI 평가 도구의 신뢰성을 확보하는 방안이 필요하다.
다섯째, AI 기반 문항 생성의 신뢰성과 타당성을 제고하기 위해 지문 생성 방식의 구조적 개선이 필수적이다. 국어과 평가에서 활용되는 지문은 단순한 기출 자료의 반복이 아니라, 평가 목표에 맞춰 변형 및 재구성되어야 하며, 이는 학습자의 독해 역량을 진단하고 평가의 변별력을 확보하는 핵심 요소로 작용한다. 따라서 AI 기반 자동 문항 생성에서는 지문이 단순한 재활용 방식이 아닌, 평가 목표와 연계된 체계적 설계를 바탕으로 이루어져야 한다. 즉, AI 기반 지문 생성은 기존 기출 지문의 변형을 넘어, 국어과 교육과정이 요구하는 독해 및 비판적 사고 역량을 반영한 새로운 텍스트를 생성하는 방향으로 발전해야 한다. 이를 위해 AI 기반 적응형 지문 생성(adaptive passage generation) 기법을 도입하는 것은 필수적이다. Gierl & Haladyna(2013)는 문항과 지문의 유기적 정합성이 평가의 타당성을 결정하는 핵심 요소임을 강조하였으며, AI가 평가 목표에 부합하는 지문을 생성하는 연구가 필요함을 제안하였다. 이에 따라 기존 기출 지문을 그대로 활용하는 방식에서 벗어나, 국어과 교육과정이 요구하는 독해 능력을 반영하여 새로운 지문을 설계하는 방향으로 나아가야 한다(Bezirhan & von Davier, 2023). 따라서 AI 기반 자동 지문 생성이 단순한 평가 자동화 도구를 넘어 학습자의 사고 과정과 평가 목표에 부합하는 방향으로 발전하기 위해서는 교육과정의 학문적 요구를 반영한 지속적인 연구가 필수적이다.
여섯째, AI 기반 평가 도구가 교육 현장에서 성공적으로 자리 잡기 위해서는 교육학, 언어학, 인공지능 연구 간 융합적 협력이 필요하다(Attali et al., 2022; Kissi et al., 2023). 예를 들어, 학습자의 읽기 전략(예: 핵심어 찾기, 논리적 연결 파악 등)과 AI가 생성한 문항 간 연계를 검토하는 연구가 이루어져야 한다. 또한 컴퓨터 지원 협력 학습(Computer-Supported Collaborative Learning, CSCL) 모델과 인간-컴퓨터 상호작용(Human-Computer Interaction, HCI) 관점을 접목하여 교사와 AI 간 협업 환경을 최적화해야 한다. 이를 통해 교사의 평가 과정과 자연스럽게 통합되는 시스템 설계를 구현하고 파일럿 연구를 통해 실질적인 효과와 활용 가능성을 검증해야 한다.
본 연구의 의의는 AI가 교사의 역할을 대체하기보다, 교사의 평가 전문성을 보완하고 학습자 중심의 평가 환경을 조성하는 ‘협력적 도구’로 기능할 가능성을 체계적으로 제시한 데 있다. 특히, AI 기반 문항 생성에서 제언된 정교한 프롬프트 설계와 Human-in-the-Loop(HITL) 접근은 평가의 공정성과 신뢰도를 높이는 동시에 교사의 업무 부담을 줄이는 방향으로 활용될 수 있음을 시사한다(Attali et al., 2022; Kissi et al., 2023). 이는 AI 기술이 단순히 기존 문항을 ‘자동화’하는 범위를 넘어, 교사와 함께 동적・적응적으로 문항을 생성하고 점검함으로써 개별 학습자의 독해 및 사고 과정을 보다 정교하게 평가할 수 있는 토대를 마련한다는 점에서 의의가 크다. 나아가 교육학, 언어학, 인공지능 연구 간 융합적 협력을 통해 학습자 반응 데이터와 실제 교실 수업 맥락을 반영한 대규모 데이터셋이 구축된다면, 교사가 주도하는 AI 평가 시스템의 신뢰성과 타당성은 한층 제고될 것이다. 궁극적으로, 본 연구가 제시하는 방향성은 교사-AI 협업 체계가 학습자 개개인의 역량과 요구를 반영하는 ‘맞춤형 평가’의 실질적 구현에 이바지할 수 있음을 보여주며, 이는 향후 교육 평가 패러다임 전환에 중요한 시사점을 제공한다.