





I. 서 론
최근 머신러닝 기법이 발달함에 따라 구조방정식모형과 의사결정나무모형을 결합한 통계 기법인 SEMtree 모형이 제안되었다(Brandmaier, Oertzen, McArdel & Linderberger, 2013). SEMtree는 구조방정식모형을 기저모형으로 설정하여 연구자의 연구 가설을 확인적으로 검증함과 동시에 연구 모형과 관련이 있는 공변수들을 모형에 투입하여 모형 모수 추정에 영향을 미치는 변수를 중요도에 따라 탐색하는 의사결정나무모형의 장점을 동시에 가진다. 또한 종단연구에서 연구자가 가지는 연구문제에 따라 기저모형을 잠재성장모형, 잠재프로파일분석, 성장혼합모형, 자기회귀교차지연 모형 등으로 폭넓게 유연한 설정이 가능하다(조영진, 노혜림, 류지훈, 2023). 이러한 장점에 기반 하여 최근 국내외 연구에서는 SEMtree을 활용한 연구가 활발히 진행되고 있다(정혜경, 이용상, 김인숙 2022; 조영진, 노혜림, 류지훈, 2022, 2023; Brandmaier et al., 2013; Grimm, Jacobucci, Stegmann & Serang, 2021; Serang, Jacobucci, Stegmann, Brandmaier, Culianos & Grimm, 2021).
SEMtree는 재귀적 분할 방법(recursive partitioning method)으로 모형 모수를 추정하게 되는데, 공변수와 관련된 조건(예: 공변수의 측정 차수, 공변수의 유형: 이분형, 리커트형, 범주형, 연속형 등)에 따라 분석 결과가 달라질 수 있기 때문에 연구자의 주의가 필요하다(조영진 외, 2023). Arnold, Voelkle & Brandmaier (2021)에 따르면 연속형 변수의 경우 이분형 변수에 비해 1종 오류가 덜 발생한다는 장점이 있는 것으로 나타났다. 반면 연속형 변수가 노드 분할을 결정하는데 걸리는 시간이 이분형 변수에 비해 길다는 점도 보고되었다. 이때 Serang 외 (2021)는 연속형 변수들을 이분형 변수로 변환하면 모형을 간명하게 만들어 모형 추정에 걸리는 시간과 부담을 줄이고 과적합 문제를 해결할 수 있다고 제안하였다. 하지만 연속형 변수를 이분형으로 변환하는 것은 정보의 손실이 발생할 수 있으므로 이러한 변수 변환은 항상 신중하게 이루어질 필요가 있다. 따라서 공변수의 유형에 대한 논의는 SEMtree 관련 연구에서 중요하게 다루어져야한다.
또한 종단연구의 측면에서 살펴보면, 수집된 패널 데이터에서 종속 변수 뿐만 아니라 공변수도 여러 차수에 측정된 값을 가지고 있기 때문에, 이를 분석에 어떻게 활용할지에 대한 연구자의 결정이 필요하다. 이는 SEMtree의 기저모형인 구조방정식모형에서 종단연구를 진행할 때 공변수가 시간의 흐름에 따라 변하지 않는다고 보거나, 시간의 흐름에 따라 변할 수 있다고 보는 가정에 따라 달리 취급하는 것과 관련이 있다(Muthén & Khoo, 1998; Preacher, 2018). 예를 들어 성별과 같은 변수는 시간의 흐름에 영향을 받지 않으므로 시간불변성(time-invariant) 설명변수로서 1차 시점의 값을 활용하고, 분석 대상의 자아존중감과 같은 심리적 변인은 시간의 흐름에 따라 변화하는 시간가변성(time-varying) 설명변수이므로, 측정된 모든 차수의 값을 모형에 투입하는 등의 의사결정이 필요하다. 이는 연구자가 연구 문제에 따라 선행 연구 기반 이론적 배경에 따른 모형 설정의 측면에서 중요한 역할을 하게 되기 때문이다.
이러한 중요성에도 불구하고, 최근 SEMtree를 활용한 국내 선행연구들에서는 모형에 투입되는 공변수의 유형에 대한 논의가 제한적이었다(정혜경 외, 2022; 조영진 외, 2022; 조영진 외, 2023). 이러한 연구들에서는 종속변수와 이론적 연관성이 있는 공변수를 선정하는 과정을 거치기는 하지만, 공변수의 특성에 대한 구체적인 논의가 이루어지지는 않았기 때문이다. 특히 모형에 투입된 공변수의 측정 시점 가정에 대해서는 데이터를 수집하기 시작한 초기 1차 시점만 분석에 활용하는 것에 국한되었다는 한계를 가진다.
따라서 본 연구에서는 SEMtree를 활용하여 종단연구를 수행할 때 분석하고자 하는 데이터의 특성이나 연구 문제에 따라 공변수를 어떻게 다루어야 할지에 대해 한국아동청소년패널 2018의 초4 패널의 실증 데이터 분석을 통해 구체적 논의를 제안하고자 한다. 특히 전반적인 교육학 연구에서 종단연구에서 접할 수 있는 공변수의 특성인 시간불변성 또는 시간가변성과 함께, 응답 척도에 따른 공변수의 형태(예: 이분형, 연속형 등)를 고려하여, 분할가지를 결정하는 분류점이 어떻게 결정되고 노드 분할에의 주요 변수가 선택되는 형태가 어떠한 차이점을 가지는지, 결과적으로 이러한 공변수의 특성이 SEMtree 모형 모수 추정 결과에 어떠한 영향을 미치는지에 대한 논의를 진행해보고자 한다. 본 연구의 연구 문제는 다음과 같다.
첫째, SEMtree 모형 분석에서 공변수의 시간의 흐름에 따른 변화(시간불변성 vs. 시간가변성) 가정에 따라 모수의 추정 결과는 어떠한 차이를 보이는가?
둘째, 공변수의 측정 척도 유형(이분형 vs. 리커트형)에 따른 SEMtree 모형 모수의 추정 결과는 어떠한 차이를 가지는가?
II. 이론적 배경
통계적 모형 검증에서 연구자가 연구 문제와 변수의 특성을 고려하여 연구 모형을 어떻게 설정할지에 대한 적절한 의사결정을 내리는 것이 필수적이다. 특히 종단연구적 측면에서 SEMtree 모형을 활용할 경우 공변수의 유형 뿐만 아니라 공변수의 측정 시점에 대한 가정(시간불변성, 시간가변성)이 노드 분할 및 모수 추정에 직접적인 영향을 미치기 때문에 중요한 이슈이다. 이 절에서는 선행 연구 결과를 통해 이러한 공변수의 특성을 SEMtree 관련 연구들에서 어떻게 다루어왔는지에 대한 종합적 논의를 제시하였다.
Brandmaier 외 (2013)에 따르면, SEMtree 모형은 구조방정식모형의 장점인 변수들 간의 관계를 이론 및 연구자의 연구 문제를 기반으로 하는 확인적 접근 방식과 의사결정나무 모형의 장점인 주요 영향 요인 변수들을 데이터에 기반해서 찾아낼 수 있다는 탐색적 접근 방식을 통합한 기계적 학습 기법이다. SEMtree에서 모형 모수의 추정 과정은 다음과 같다. 먼저, 연구 문제를 검증하기 위해 공변수를 제외하고 종속 변수만 고려하여 구조방정식에 기반한 기저 모형(template model)을 설정한다. SEMtree를 활용한 선행연구들은 경로모형(Alhadabi, 2021), 요인분석모형(Ammerman, Jacobucci, Turner, Dixon-Gordon & McClosky, 2020; Brandmaier et al., 2013), 잠재성장모형(Brandmaier et al., 2013; Jacobucci, Grimm & McArdle, 2017; 정혜경 외, 2022; 조영진 외, 2022), 성장혼합모형(Alhadabi, 2022; 조영진 외, 2023) 등을 기저모형으로 설정했다. 이때 공변수를 제외한 종속변수만 고려한 기저모형의 우도를 계산하게 된다. 일반적으로 구조방정식 모형의 우도(lnL)는 다음과 같이 계산된다(Preacher, 2018).
여기서 p는 측정차수, yi는 개인 i로부터 측정된 변수의 값, 2π는 상수이고, 모형의 모수인 Σ = ΛΨΛ′+Θ는 공분산 행렬(Λ=요인부하량, Ψ=요인 분산·공분산, Θ=오차 분산·공분산), μ=τ+Λα는 평균벡터(τ=절편, Λ=요인부하량, α=잠재변수의 평균)을 의미한다. 위에 제시된 우도를 최대화하는 모형 모수의 값을 추정하게 된다.
이러한 기저모형을 기반으로 트리구조인 T, 기저모형인 M, 모형 모수인 θ로 구성된 SEMtree 모형을 상세화한다. 이때 기저모형 M은 연구자의 연구 문제에 기반하여 구조방정식 모형 중 하나로 지정된다. SEMtree 모형 모수θ의 추정 과정은 다음과 같다. 우선, 투입된 각 공변수에 따라 데이터를 분할하게 된다. 만약 공변수가 0과 1로 이루어진 이분형 변수라면, 공변수를 0과 1로 지정했을 때 각각에 따라 기저모형의 우도값을 계산하게 된다. 다음으로 앞서 계산된 공변수를 제외한 기저모형의 우도를 기준으로 각각의 우도비를 계산하여 통계적으로 유의할 때 노드 분할을 시행하게 된다. 이때 계산되는 우도비 Γ는 다음과 같다.
여기서 lnL(θ̂i | Di)는 해당 공변수가 가지는 값에 따라 분할된 데이터 Di 각각에서의 우도를, lnL는 앞서 언급한 공변수를 제외한 기저모형의 우도를 나타낸다. 이때 θ̂i 는 해당 공변수의 값으로 인해 분할된 데이터에서 추정될 모형 모수들을 의미한다. 계산된 우도비 Γ에 대한 통계적 유의성을 검증할 때는 (k-1)m 자유도에 기반한 카이자승(χ2)검증을 실시하게 된다. 여기서 k는 투입된 공변수가 가지는 값(이분형의 경우, 0과 1)의 수, m은 모형에서 추정되는 자유 모수의 수를 나타낸다.
트리구조인 T를 지정할 때, 연구자는 SEMtree 모형을 설정하는 과정에서 기저모형의 특정 모수를 각 집단마다 동일하게 고정하거나, 끝 노드의 표본수 또는 노드 분할 가지 수 등의 모형과 관련된 조건을 설정한다. 이를 통해 연구문제를 검증하기에 가장 적합하면서 동시에 지나치게 과적합되는 문제를 방지할 수 있다.
SEMtree 모형에 투입되는 공변수의 특성은 노드 분할에 직접적인 영향을 미치기 때문에 모형의 모수 추정에 중요한 영향을 미치게 된다. 특히 공변수의 유형(연속형 또는 이분형)은 노드 분할에 걸리는 시간이나 모형의 과적합 문제를 야기하기도 한다. 이에 따라 Serang 외 (2021)에서는 모형의 간명성과 효율성을 높이기 위해 공변수를 연속형에서 이분형으로 변환하게 되면, 특정한 데이터 상태(이상치나 결측치가 많은 경우)나 데이터의 정상성이 많이 벗어나는 경우, 혹은 특정 응답 집단이 지나치게 많거나 적은 경우에도 통계적 검정력을 높일 수 있고, 모형 모수 추정의 수렴 이슈를 다루기에 용이해진다고도 언급하였다.
반면 일반적으로 연속형 변수가 이분형 변수에 비해 정보를 많이 가지고 있기 때문에, 이분형 변수에 비해 연속형 변수를 공변수로 투입하는 것이 결과 해석에서의 장점이 존재한다고 본다. 특히 의사결정나무모형의 관점에서 보면 연속형 변수의 경우 공변수의 노드 분할을 위한 분할점을 연구자의 임의가 아닌 데이터를 기반으로 자동으로 탐색할 수 있다(Arnold et al., 2021; Grassi & Tarantino, 2023). 또한 공변수가 연속형인 경우에는 노드 분할의 최적점을 찾는 단계가 추가적으로 제시되므로 (Merkle & Shaffer, 2011; Zeileis, Hothorn & Hornik, 2008) 연구자가 임의적으로 절단점을 정하는 이분형 변수로의 변환할 때 발생할 수 있는 단점을 방지할 수 있다.
국내외 SEMtree를 활용한 연구에서 고려한 공변수의 형태에 관한 예시들은 다음과 같다. Arnold 외 (2021)에서는 데이터 시뮬레이션 연구를 통해 연속형 변수만 투입한 SEMtree가 이분형 변수만 투입한 SEMtree에 비해 1종 오류가 감소하여 모형 모수 추정에서 더 정확한 결과를 얻을 수 있었지만, 추정에 소요되는 시간이 더 길었으므로 덜 효율적이라는 점을 밝혀내었다.
조영진 외 (2022)의 연구에서는 ECLS-K 2011 자료의 6시점에서 측정된 읽기 성취도 점수를 종속변수로 하는 잠재성장모형을 연구모형으로 활용하여, 사회적 행동 관련 4개 변수와 인구통계학적 4개 변수의 총 8개를 공변수로 모형에 투입하였다. 이때 이중언어 변인은 이분형 변수로 활용하고, 인종 변인은 4개의 변인으로 더미코딩하여 분석에 활용하였다. 나머지 6개의 공변수는 연속형으로 모형에 투입하였다.
정혜경 외 (2022)에서는 한국아동․청소년패널조사 2018의 중학교 1학년부터 3학년의 창의성에 대한 잠재성장모형을 연구모형으로 SEMtree를 분석했는데, 공변수로는 중학교 1학년 시기의 자기 및 관계 인식과 관련된 7개 변수, 습관 및 행동 관련 11개 변수, 마지막으로 지역과 성별에 대한 구인을 포함하여, 총 20개의 공변수를 고려하였다. 이 연구에서는 SEMtree 모형에 활용된 대부분의 공변수가 연속형이었다. 이 중 시간 관련 변수들은(예: 1=전혀 안함~7=4시간 이상) 서열변수로 포함하였으며, 지역변수와 성별변수는 유목변수로 모형에 투입되었다.
공변수의 유형에 비해 공변수의 시간에 따른 가정에 대한 논의는 앞서 살펴본 공변수의 측정 척도에 대한 논의보다 상대적으로 미비한 실정이다. 하지만 선행된 SEMtree모형 연구들에서 기저모형으로 주로 채택되는 잠재성장모형을 활용한 종단연구들에서 이미 중요하게 다루어지고 있는 주제 중 하나이므로 살펴볼 필요가 있다.
잠재성장모형은 종속 변수의 성장궤적을 추정할 수 있다는 점에서 사회과학 분야에서 광범위하게 활용되어왔다. 잠재성장모형에서 성별이나 인종과 같이 시간불변성 공변수를 모형에 설명변수로 활용할 때([그림 1]의 왼쪽), 이는 공변수의 측정 초기값을 잠재성장모형에 설명변수로 그대로 투입하기 때문에 공변수가 잠재성장모형 모수인 초기값 및 기울기에 직접적으로 어떠한 영향을 주는지에 대한 논의가 가능하다는 장점을 가진다(Muthén & Khoo, 1998). 반면, 시간가변성 공변수의 경우 ([그림 1]의 오른쪽), 시간의 흐름에 따라 공변수가 변화한다고 보는 관점(예: 자아존중감, 우울 등)으로, 모든 차수에 측정된 값을 공변수로 모형에 투입한다(Muthén & Khoo, 1998). 이러한 경우 각 차수에 측정된 모든 공변수 값들이 성장 궤적을 추정하는 모수들이 아니라, 각 차수에 상응하는 종속 변수에 직접 영향을 주는 설명변수로 취급된다. 이는 측정 차수에 따라 공변수와 종속 변수의 관계를 파악할 수 있다는 장점을 가진다. Preacher (2018)에 따르면, 공변수를 시간불변성 또는 시간가변성으로 취급할지에 대해 통계적 기준보다는 연구자가 연구 문제의 특수성, 공변수에 대한 선행 연구들의 결과 등을 고려하여 공변수를 취급할 지에 대한 판단을 내려야 한다고 제안하고 있다. 따라서 잠재성장모형을 기반으로 하는 통계적 분석에서는 반드시 자료의 특성 및 연구 문제, 선행 연구 결과 등에 따라 공변수를 각 차수의 종속 변수에 직접적인 영향을 주는 시간가변성 설명변수로 취급하거나 종속 변수의 변화궤적을 나타내는 모형 모수의 시간불변성 설명변수로 다룰지에 대한 논의가 필요함을 알 수 있다.
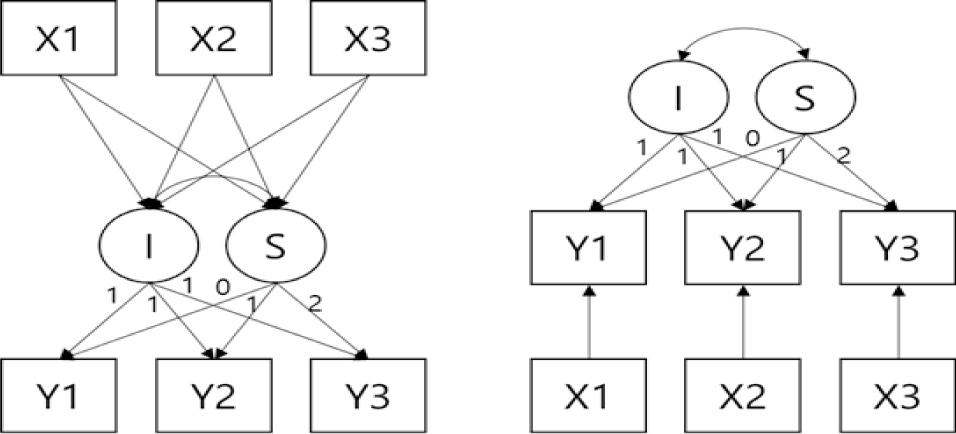
SEMtree 선행 연구들은 공변수의 시간의 흐름에 따라 변하지 않는다고 가정하는 시간불변성 변수로 취급하거나, 이러한 가정을 고려하지 않는 경향을 보여주었다. Brandmaier 외 (2013)의 연구에서는 Wechsler Intelligence Scale for Children (Wechsler, 1949)를 분석할 때 이분형(성별)과 연속형(나이, 부모의 교육수준) 모두 1차 시점 값을 SEMtree 모형에 투입하였다. 조영진 외 (2022)에서 ECLS-K 2011 자료의 6시점 읽기 성취도 점수를 분석할 때, 성별 또는 인종과 같은 시간에 따라 변하지 않는 공변수를 모형에 투입하거나 (인구통계학적 모형), 사회적행동 변인의 경우 측정 시기에 대한 고려는 따로 하지 않은 모형(완전SEMtree 모형)을 활용하였다. 또한 조영진 외 (2023)에서는 한국교육종단연구 2013의 5시점 국어성취도 변화 궤적을 추정할 때, 1차 시기인 초등학교 5학년의 공변수 값들을 활용하였다. 정혜경 외 (2022)의 청소년의 창의성 성장 궤적을 분석한 연구에서도 시간불변성 가정에 따라 측정 초기 시점인 중학교 1학년 시기의 공변수들을 투입하여 모수 추정 결과를 보고하였다.
III. 연구 방법
본 연구에서는 한국청소년정책연구원에서 수행한 한국아동청소년패널 2018 (Korean Children and Youth Panel Survey 2018; 이하 KCYPS 2018) 초등학교 4학년 패널 1차(2018년)부터 5차(2022년)까지의 데이터를 분석하였다. 총 표본 수는 1차 기준으로 2,607명이며, 남학생이 1,313명(50.4%), 여학생이 1,294명(49.6%)으로 구성되어 있다. 결측치의 경우 최대 11.4%까지 존재했으나, 본 연구에서는 완전정보최대우도법(full-information maximum likelihood)를 사용하여, 결측치가 존재하는 케이스의 우도를 개별적(casewise likelihood)으로 다루어 모형 모수를 추정했기 때문에, 2,607명의 자료가 모두 분석에 활용되었다.
종속 변수는 개인발달 영역 중 행복감에 해당하는 변수로 1차부터 5차까지 4개의 세부 문항(예: 문 9. 아래 문항을 읽고 자신을 가장 잘 설명한다고 생각하는 항목에 응답해 주십시오. “1) 전반적으로 나는 …”, “2) 다른 사람과 비교했을 때 나는…”, “3) 전반적으로 아주 행복한 사람들이 있다. 그들은 무슨 일이 있어도 개의치 않고 즐겁게 지내는 편이다. 나는 …”, “4) 전반적으로 아주 불행한 사람들이 있다. 그들은 특별히 우울한 일이 없어도 행복하지 않아 보인다. 나는 …”)으로 측정되었고 4점 척도(1= 전혀 그렇지 않다 ~ 4=매우 그렇다)의 응답값을 가진다. 가장 마지막 문항은 부정형 문장이기 때문에 역코딩하였다. 분석에서는 각 측정차수의 4개 문항의 평균값을 구하여 1차부터 5차까지의 종속변수로 모형에 투입하였다. <표 1>에는 종속 변수의 기술통계량이 제시되어 있다. 평균값을 살펴보면, 1차부터 5차까지 계속 감소하는 양상을 보였다. 이는 초등학교 고학년 시기부터 중학교 시기까지 행복감이 감소하는 추세였음을 알 수 있다. 1차부터 5차까지 행복감 변수의 Cronbach’s alpha 값은 0.68~0.77로 나타났다.
본 연구에서 행복감에 주요한 영향을 미치는 공변수로 선정한 변수들은 <표 2>에 제시하였다. 모든 공변수들은 1차부터 5차까지 4점 척도(1=전혀 그렇지 않다~4=매우 그렇다)로 측정되었다. 또한 부정형 문장으로 구성된 문항이 존재하는 변수의 경우는 역코딩하였다(<표 2> 참조). 모든 공변수는 세부 문항들의 평균값으로 모형에 투입되었다.
<표 2>에 제시된 1차부터 5차까지의 기술통계량을 살펴보면, 공변수들 중 우울이 평균이 가장 낮았고(M=1.53~1.75, S.D.=0.53~0.63), 양육태도 중 따스함의 평균이 가장 높게 나타났다(M=3.20~
3.58, S.D.=0.53~0.58). 총 27개의 공변수들 중 부정적 의미의 척도들(정서문제 - 주의집중, 공격성, 신체증상, 사회적 위축, 우울; 친구관계 - 부정적 관계; 양육태도 - 거부, 강요, 비일관성)은 4점 척도의 중앙값인 2.5보다 평균이 낮게 나타났고, 긍정적 의미의 척도들(삶의 만족도; 학업열의 – 헌신; 자아존중감; 협동심 – 집단촉진, 팔로워십, 갈등문제해결; 끈기 – 그릿; 친구관계 – 긍정적 관계; 교사관계 – 접근 가능성, 민감성, 신뢰성, 수용성; 양육태도 – 따스함, 자율성지지, 구조제공)은 2.5보다 평균이 높았다. 하지만 학업열의를 나타내는 3개의 변수(활기, 효능감, 몰두)는 이러한 패턴이 나타나지는 않았다. 신뢰도의 경우 모든 척도의 Cronbach’s alpha=0.6~0.91의 값을 보였다.
본 연구에서는 연구 문제에 따라 3개의 SEMtree 모형을 분석했다. 모형 1에서는 공변수들이 시간의 흐름에 따라 변하지 않는다고 가정하였기 때문에 가장 초기에 측정된 차수, 즉 모든 공변수의 1차 연도 값을 분석에 설명변수로 투입하였다. 또한 리커트 척도로 측정된 값을 그대로 분석에 활용하였다. 모형 2의 경우 시간의 흐름에 따라 공변수들이 변한다고 가정하였기 때문에 공변수의 모든 측정 차수의 값들을 분석에 투입하였다. 이때도 4점 리커트 척도로 측정된 값을 변환하지 않았다. 모형 3에서는 모든 공변수가 4점 척도로 측정되었기 때문에, 각 차수의 평균을 구한 뒤, 평균이 4점 척도의 중앙값인 2.5미만인 경우에 0, 2.5이상인 경우를 1로 변환하여 이분형 변수를 생성하였다. 다만, 모형 3에서는 모형 1과 마찬가지로 공변수의 값이 시간의 흐름에 따라 변하지 않는다고 가정하였다.
각 모형의 분석 절차는 우선, 종속 변수인 행복감의 시간의 흐름에 따른 변화패턴에 따라 무성장모형부터 삼차성장모형의 모형 적합도를 비교하여 가장 적합한 기저모형을 설정한다. 다음으로 공변수의 유형과 시간의 흐름에 따른 가정에 맞게 상세화 한 세 개의 연구모형(모형 1부터 모형 3)을 기반으로 SEMtree 모형 모수를 추정한다. 이때 기저모형에 비해 추정된 모수의 이질성이 최대화되는 모형, 즉 우도비검증 방법을 통해 각 연구 모형별 최종 모형을 도출해낸다.
본 연구의 세 모형을 비교할 때의 기준은 다음과 같다. 첫째, 노드 분할 및 끝 노드의 개수가 어떻게 다른지 비교하였다. 노드 분할이 더 많이 되어 끝 노드가 더 많이 추정되는 경우 모형 모수가 이질적인 집단이 더 많이 도출된 것을 의미하므로, 분석 결과의 해석적 측면에서 유리할 것이기 때문이다. 둘째, 노드 분할 시 공변수가 중복 선정되는 경우가 더 많은지 혹은 더 적은지에 대해서도 살펴보았다. 중복 선정되는 공변수가 적게 나타날수록 도출된 집단의 특성에 대한 설명변수를 더 많이 확보할 수 있기 때문에 이 또한 모형 해석적 측면에서 유리하다고 보았다. 셋째, 연속형 변수만 투입한 경우(모형 1과 모형 2)와 이분형 변수로 변환한 경우(모형 3) 노드 분할점이 어떻게 다른지, 특히 모형 3의 경우 연속형 공변수를 이분형으로 변환할 때 척도의 중앙값인 2.5를 기준으로 삼았으므로 이 기준점에 비해 모형 1과 모형 2가 어떠한 분할점이 설정되는지를 살펴보았다. 이러한 기준은 선행 연구인 Jacobucci 외 (2017)와 Arnold 외 (2021)의 연구를 참고하였다.
분석에는 R 프로그램 패키지 중 semtree (Brandmaier & Prindle, 2018)를 사용하였다. 이는 현재 SEMtree 모형 분석에서 가장 많이 쓰이는 프로그램 패키지로 Openmx 언어로 기저 모형인 잠재성장모형을 설정할 수 있다. 모형 모수 추정에서의 과적합을 방지하기 위해 노드 분할과 끝 노드의 표본수가 200개가 되도록 설정하였는데, 이는 잠재성장모형의 최소 표본 수 기준(Maydeu-Olivares, 2017; McNeish & Harring, 2017)에 따른 것이다. 모수 추정 방식에는 나이브(naive) 방식이 사용되었고, 우도비 검증에서는 p-value가 0.05을 기준으로 하였다. 이는 semtree 패키지의 기본값을 활용한 것이다(Brandmaier & Prindle, 2018).
IV. 연구 결과
SEMtree 모형을 분석하는 첫 단계로 기저모형인 잠재성장모형을 분석하여 그 결과를 <표 4>에 제시하였다. 무성장모형의 경우 시간의 흐름에 따라 종속변수의 변화가 발생하지 않았다는 것을 의미하며, 일차성장모형의 경우 일정하게 증가하거나 감소하는 선형 변화 패턴을 나타내며, 이차성장모형의 경우 증가감소, 또는 감소증가의 곡선적 변화 양상을 추정할 수 있다. 모형 적합도를 비교한 결과 가장 작은 AIC, BIC, SABIC 값을 보였고, 나머지 모형 적합도 값이 기준(Hu와 Bentler, 1999; CFI>.90, TLI>.90, RMSEA<.08)에 부합했다. 3차성장모형의 경우 수렴하지 않아 기저모형의 모수가 추정되지 않았다. 따라서 본 연구에서는 종속 변수인 행복감의 시간의 흐름에 따른 변화 패턴을 설명하기에 이차성장모형을 가장 적합한 모형으로 선정하였다.
기저모형인 이차성장모형의 분석 결과는 <표 5>에 제시되었다. 추정된 모수 값을 살펴보면, 초기값 평균은 3.37로 4점 척도의 중앙값인 2.5보다 높은 것으로 나타났다. 이는 1차연도인 초등학교 4학년 시기 학생들의 행복감이 중앙값보다는 조금 높은 수준이었음을 의미한다. 1차 기울기 평균의 경우 부적인 값으로 나타났는데, 시간의 흐름에 따라 행복감이 점차 감소하는 경향이 있음을 알 수 있다. 2차 기울기 평균의 경우 정적인 값이었으므로, 행복감이 점차 감소하는 양상이 가속화되는 패턴이었음을 나타낸다. 초기값과 1차 기울기, 1차 기울기와 2차 기울기는 각각 통계적으로 유의한 부적인 공분산 값들을 보였는데, 이는 초등학교 4학년 시기의 행복감이 높은 학생일수록 행복감의 감소 패턴이 나타났고, 시간이 지남에 따라 이러한 변화 양상이 더욱 두드러지게 나타났음을 의미한다.
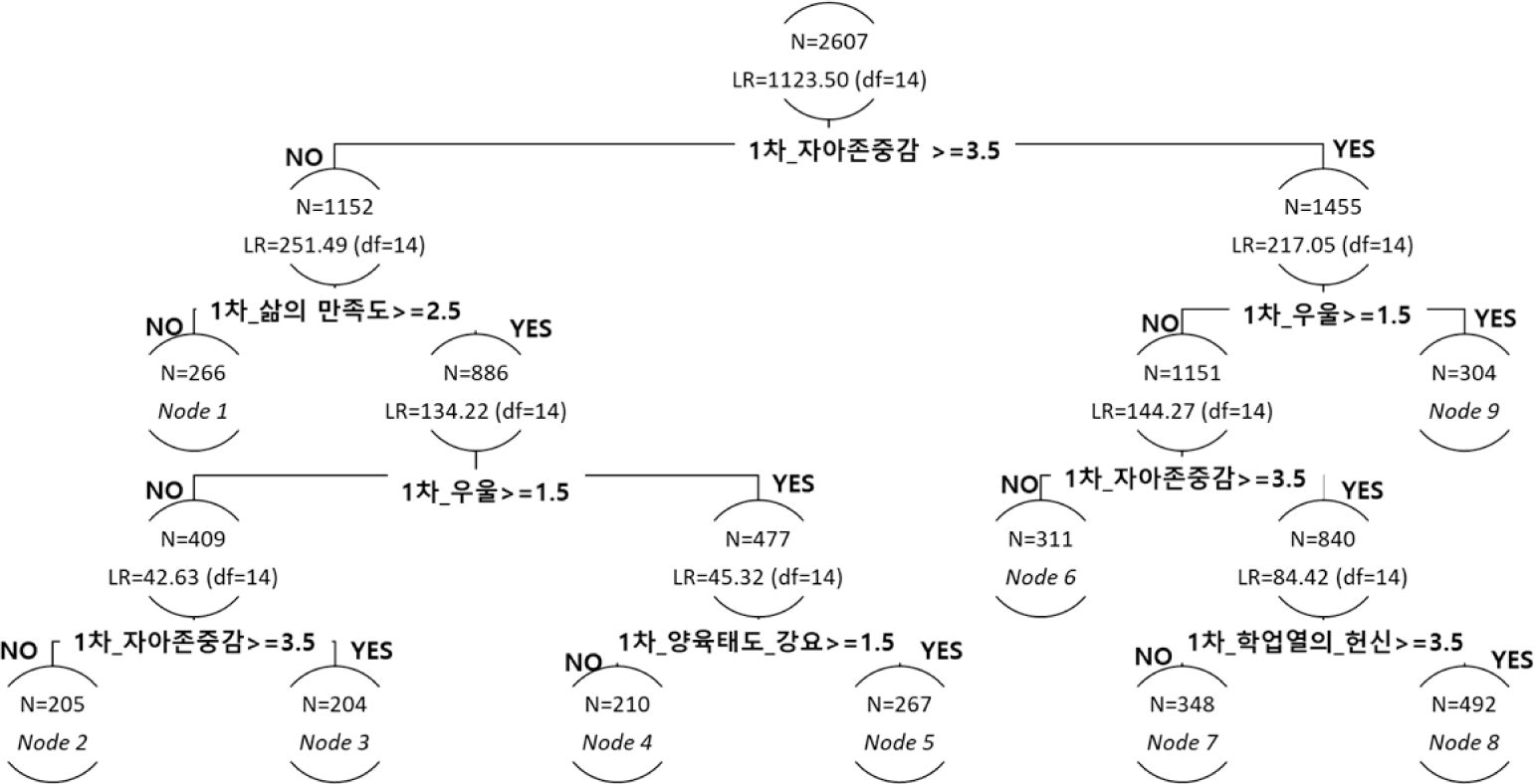
본 연구의 연구 문제에 따른 세 개의 연구 모형의 경로도가 [그림 2]부터 [그림 4]에 제시되어 있다. 모형 1의 경우([그림 2] 참조), 8개의 분할가지를 통해 총 9개의 끝 노드가 산출되었고 5개의 공변수(1차 연도의 자아존중감, 삶의 만족도, 우울, 양육태도 중 강요, 학업열의 중 헌신)가 노드 분할에 활용되었다. 이 중 자아존중감과 우울은 노드 분할 변수로 중복 선정되었다. 또한 자아존중감, 삶의 만족도, 헌신의 경우 4점 척도의 중앙값인 2.5이상에서 노드 분할점이 설정되었고, 우울과 양육태도 중 강요는 척도의 중앙값보다 작은 1.5점에서 노드가 분할되었다.
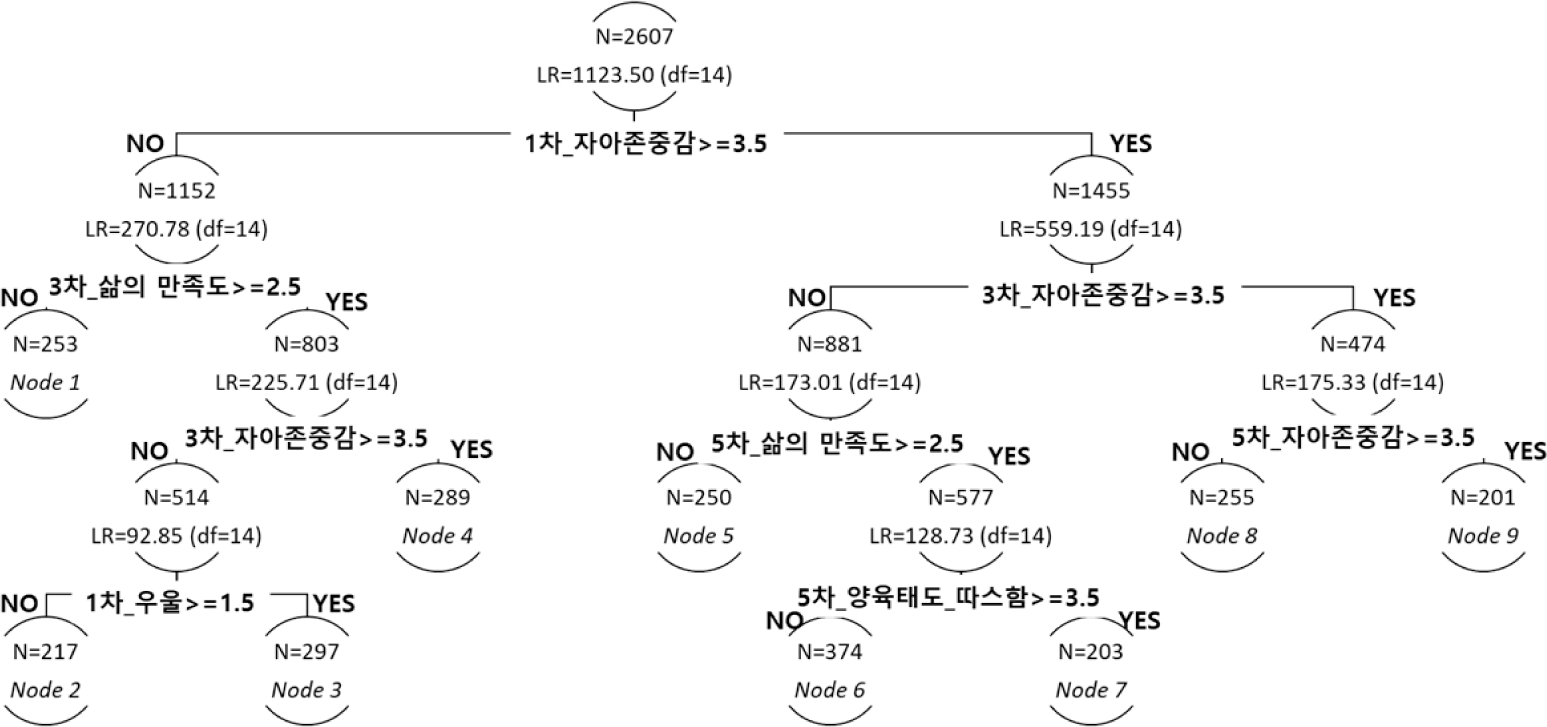
모형 2([그림 3] 참조) 또한 8개의 분할 가지를 통해 9개의 끝 노드가 산출되었다. 하지만 모형 1과 달리, 자아존중감, 삶의 만족도, 우울, 양육태도 중 따스함의 공변수 4개가 노드 분할에 활용되었다. 이 중 자아존중감은 1차, 3차, 5차에 측정된 값이, 삶의 만족도는 3차와 5차에 측정된 값이 각각 노드 분할 변수로 선정되었다. 우울을 제외한 모든 공변수가 4점 척도의 중앙값인 2.5점보다 높은 값에서 노드 분할점이 설정되었다.
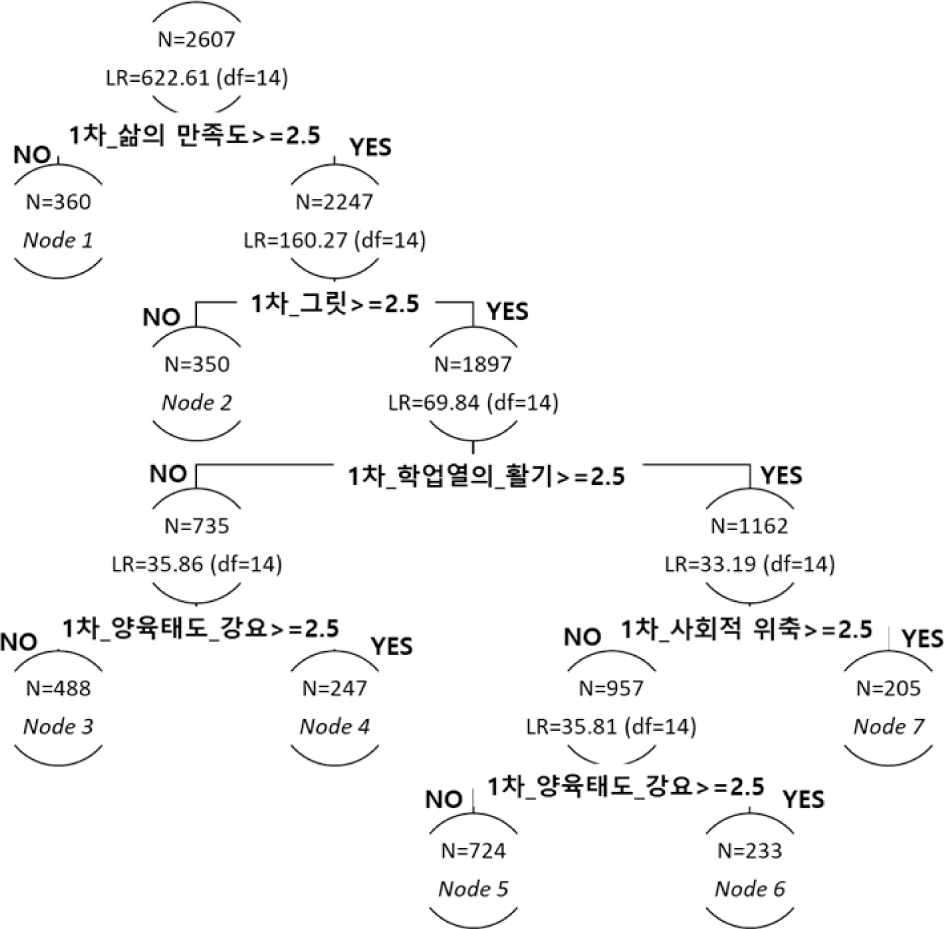
모형 3의 결과([그림 4] 참조)를 살펴보면, 총 5개의 분할 가지를 통해 6개의 끝 노드가 추정되었다. 공변수를 투입할 때 4점 척도의 중앙값인 2.5를 기준으로 이분형 변수로 변환했기 때문에 분할점은 모두 2.5로 설정되어있다. 5개의 공변수(1차 연도의 삶의 만족도, 그릿, 학업 열의 중 활기, 양육태도 중 강요, 사회적 위축)가 노드 가지 분할에 활용되었다. 이 때 양육태도 중 강요는 노드 분할 변수로 중복 선정되었다.
본 연구의 연구모형들의 노드별 모수 추정치를 살펴보기 위해 표본 수가 가장 많은 노드, 초기치 평균이 가장 높거나 가장 낮은 노드들의 결과를 <표 5>부터 <표 7>에 제시하였다. 모형 1의 끝 노드들 중 가장 많은 수의 표본(N=492)이 포함된 노드 8의 결과를 살펴보면 (<표 5> 참조), 1차 연도의 자아존중감이 3.5 이상, 1차 우울이 1.5 미만, 학업 열의 중 헌신이 3.5이상인 특징을 가지고 있었다. 다른 노드들과 비교했을 때 노드 8은 초기값의 평균(3.820) 또한 가장 높았고, 1차 기울기의 평균은 부적인 값(-0.385)을, 2차 기울기 평균은 정적인 값(0.051)로 나타났다. 이는 초등학교 4학년 시기에 행복감이 가장 높았던 집단의 경우 시간이 지남에 따라 행복감이 감소하는 경향을 보였으며 이러한 변화 패턴이 가속화됨을 의미한다.
반면, 모형 1에서 초기치 평균이 가장 낮았던 노드 1(N=266)의 경우 1차 연도의 자아존중감이 3.5미만이었고 1차 연도의 삶의 만족도 또한 2.5미만이었다. 초기값 평균(2.767)의 경우 노드 8보다 낮았는데, 1차 기울기의 평균은 정적인 값(0.082)을, 2차 기울기 평균은 부적인 값(-0.013)으로 나타났다. 이는 노드 8과 비교했을 때, 반대의 변화 양상을 보이는 것으로, 시간이 지남에 따라 행복감이 증가하기는 했지만 변화폭이 점차 둔화됨을 의미한다.
<표 6>에 제시된 결과를 보면, 모형 2의 경우 가장 많은 수의 표본이 포함된 노드 6 (N=374)은 1차 연도 자아존중감은 3.5이상, 3차 연도 자아존중감은 3.5 미만, 5차 연도 삶의 만족도는 2.5 이상, 5차 연도 양육태도 중 따스함이 3.5 미만인 특성을 가진 집단이었다. 행복감의 변화 궤적을 살펴보면, 초기값 평균이 3.592로, 초기값 평균이 가장 높았던 노드 7 (N=203)의 초기값 평균(3.675)과 유사했다. 노드 6과 노드 7은 모형 모수의 추정치도 비슷한 결과를 보였는데, 1차 기울기의 경우 부적인 평균 값을, 2차 기울기의 경우 정적인 평균 값을 보였다. 이는 초등학교 4학년 시기에 행복감이 높았던 학생들의 경우 시간이 지남에 따라 행복감이 감소하는 양상을 보였고 변화폭이 점차 커졌음을 의미한다.
모형 2에서 초기값 평균(2.877)이 가장 낮았던 노드 1(N=253)의 경우, 1차 연도 자아존중감이 3.5미만이었고, 3차 연도 삶의 만족도가 2.5 미만인 것으로 나타났으므로, 공변수의 노드분할점이 노드 6, 노드 7과는 다르게 설정되었다. 하지만 부적인 1차 기울기 평균 값, 정적인 2차 기울기 평균 값은 노드 6, 노드 7과 같았으므로, 행복감이 시간이 지남에 따라 점차 감소하고 변화가 가속화 된다는 변화 양상에서는 같은 결과를 보여주었다.
모형 3의 결과를 살펴보면(<표 7> 참조), 가장 많은 수의 표본이 포함된 노드 5(N=724)의 경우 1차 연도 삶의 만족도, 그릿, 학업 열의 중 활기가 중앙값인 2.5 이상, 사회적 위축과 양육 태도 중 강요가 2.5 미만의 특성을 보였다. 행복감의 초기값 평균은 3.626으로 추정된 노드들 중 가장 높은 것으로 나타났다. 1차 기울기 평균의 경우 부적인 값(-0.291)을, 2차 기울기 평균의 경우 정적인 값(0.038)을 보여 시간이 지남에 따라 행복감이 점차 감소하고 이러한 변화 폭이 가속화됨을 보여주었다. 반면 행복감의 초기치 평균(2.834)이 가장 낮은 노드 1(N=360)의 경우 1차 삶의 만족도가 2.5 미만인 것으로 나타났다. 노드 1은 1차 기울기 평균이 정적인 값(0.085)을, 2차 기울기 평균(-0.017)이 부적인 값을 보여 노드 5와는 다른 행복감 변화 패턴을 보여주었다.
V. 결론 및 제언
본 연구에서는 SEMtree를 활용한 교육학 연구에서 공변수의 종단적 변화에 따른 가정(시간불변성과 시간가변성)과 유형(이분형과 리커트형)에 따라 모수 추정 결과가 어떻게 달라지는지에 대해 살펴보았다. KCYPS 2018 초등학교 4학년 패널의 행복감에 대한 SEMtree 모형 분석 결과는 다음과 같다. 첫째, 시간불변성을 가지는 공변수만 투입한 경우(모형 1)와 시간가변성을 가지는 공변수만 투입한 경우(모형 2)를 비교할 때 노드 분할 가지(8개)와 끝 노드(9개)의 수에 차이가 없었다. 하지만 모형 1의 경우 5개의 공변수가 노드 분할에서 3번의 중복 선정이 생긴데 반해, 모형 2의 경우 공변수의 중복 선정이 발생하지 않았다. 다만, 일부 공변수(자아존중감, 삶의 만족도)가 다른 차수에 측정된 값이 노드 분할에 활용된 것으로 나타났다. 이는 앞서 Muthén 과 Khoo (1998), Preacher (2018)에서 언급한 대로, SEMtree의 기저모형인 구조방정식 모형에서 종단 연구를 수행할 때 선행 연구 결과에 기반한 연구 모형이 종속 변수 뿐만 아니라 공변수 또한 시간가변적 특성이 있음을 고려해야 한다는 점을 시사한다.
둘째, 리커트형 공변수만 투입한 경우(모형 1: 8개의 분할가지, 9개의 끝노드)가 이분형 공변수로 변환한 경우(모형 3: 5개의 분할가지, 6개의 끝노드)에 비해 분할 가지와 끝 노드의 수가 더 많았다. 반면 모형 1에 비해 모형 3에서는 노드 분할에서 공변수가 중복 선정되는 경우가 적었다. 이렇듯 연속형 변수가 더 많은 노드 분할이 발생하기는 하지만 노드 분할 공변수의 중복이 더 많이 발생했다는 본 연구의 결과는, 노드 분할에서 이론적 중요도보다는 데이터 특성에 지나치게 의존하여 선택되는 경향이 있다는 Serang 외 (2021)의 연구 결과를 뒷받침하는 것이다. 연속형 변수의 경우 모형 자체에서 분할점을 자동으로 선택하게 되는데, Serang 외 (2021)의 연구에서는 연속형 변수가 실제로 노드 분할에 중요하지 않아도, 노드 분할에 필요한 분할점을 계산하는 과정에서 연속형 변수는 분할점을 찾는 지점이 많아 노드 분할에 중요한 변수로 선택될 수 있음을 지적하였다. 즉 연속형 변수는 변수의 실제 중요도가 아닌 변수의 유형 특성 때문에 노드 분할에 선택되거나 중복된 변수로 선택될 확률이 높으므로, 연속형 변수의 경우 연구자의 이론적 가설이나 연구 문제에 따라 연구자가 분할점을 이론적으로 결정할 필요가 있음을 시사한다. 이는 끝 노드로 분할되는 가지에 특정 변수가 지나치게 중복되면, SEMtree 모형 분석 결과인 끝 노드의 특성을 설명하기 어려워진다는 점에서 더욱 중요하다.
본 연구는 다음과 같은 의의를 가진다. 우선, SEMtree 모형은 종속 변수의 변화 궤적을 통한 종단연구와 함께 영향 요인에 대한 탐색도 가능하며, 이에 따른 끝 노드를 추정함으로써 이질적 집단을 구분해 낼 수 있다는 점에서 기존의 구조방정식 모형보다 폭넓은 연구 문제를 다루는데 유용하다. 특히 본 연구 결과인 노드별 해석을 통해, 연구자가 이론적 연구 가설에 맞게 기저 모형을 설정하는 확인적 모형의 특성을 보임과 동시에 공변수들로부터의 정보(예: 공변수의 노드 분할에서의 절단점)를 통해 탐색적으로 집단 특성을 설명할 수 있다는 장점을 가질 수 있음을 보여주었다. 나아가 이 연구에서는 SEMtree 모형을 활용할 때는 온전히 데이터에 의존하는 탐색적 방식뿐만이 아니라, 공변수와 관련된 특성을 연구자가 연구 목적에 맞게 모형에 적절히 투입할 필요가 있음을 실증적으로 보인 것에 의의가 있다. 조영진 외 (2023)에서 언급되었던 공변수의 수와 유형(이분형, 범주형, 연속형), 측정 차수 및 시간의 흐름에 따른 변화 정도에 대한 가정(시간불변성 또는 시간가변성) 뿐만 아니라, 노드 분할에서의 분할점 설정이나 연속형 공변수를 이분형으로 변환하는 방법(척도의 중앙값 기준) 등에 대해서도 생각해 볼 필요가 있음을 본 연구 결과를 통해 시사한다.
본 연구의 한계점을 다음과 같다. SEMtree가 제안된 시점이 비교적 최근이기 때문에 선행 연구과 마찬가지로 본 연구 또한 실증 데이터 분석을 실시하여 연구 문제를 탐구하였는데, 새로 제안된 모형의 특성을 파악하고 분석에 적용하는 일련의 과정을 살펴볼 수 있다는 장점을 가진다 (Boulesteix et al., 2020; Morris et al., 2019). 하지만 Brandmaier 외 (2013)에서 지적했듯이, 노드 분할에서의 조건인 가지의 수, 트리의 깊이, 끝 노드의 표본 수, 우도비 검정에서의 조건(예: p-value 기준, Bonferroni의 사후 검정 방법 등)을 시뮬레이션 연구를 통해 보다 구체적으로 검증해 볼 필요가 있다. 특히 노드 분할에서 공변수가 중복으로 선정되는 것에 대해서 특히 주목해야 한다. Serang 외(2021)의 연구에서는 이러한 중복이 공변수의 유형(이분형, 연속형)에 따른 차이라고 지적했지만, 본 연구의 결과를 통해 또 다른 이유(예: 공변수의 측정 시점에 따른 가정에서의 차이-시간불변성 또는 시간가변성)와 같은 논의들이 추가적으로 필요함을 알 수 있다. 나아가 SEMtree의 모수 추정 방법에 따른 차이도 고려해볼 필요가 있다. Arnold 외 (2021)에 따르면 이분형 변수의 경우 기존의 나이브 방법이 가장 적합하였으나, 범주형과 연속형 변수에서는 CSP(cumulative score process)에서 각각 이중 최댓값(double maximum: DM; Hjort & Koning, 2002)과 WDM(weighted double maximum; Merkle & Zeileis, 2013)이 상대적으로 적합한 추정방식인 것으로 제안하였다. 따라서 향후 SEMtree 연구의 실제적 가이드라인을 시뮬레이션 연구를 통해 정립하는 방향의 후속 연구들이 추가적으로 진행되어야 할 것이다.